Divya Siddarth, Daron Acemoglu, Danielle Allen, Kate Crawford, James Evans, Michael Jordan, E. Glen Weyl The dominant vision of artificial intelligence imagines a future of large-scale autonomous systems outperforming humans in an increasing range of fields. This “actually existing AI” vision misconstrues intelligence as autonomous rather than social and relational. It is both unproductive and dangerous, optimizing for artificial metrics of human replication rather than for systemic augmentation, and tending to concentrate power, resources, and decision-making in an engineering elite. Alternative visions based on participating in and augmenting human creativity and cooperation have a long history and underlie many celebrated digital technologies such as personal computers and the internet. Researchers and funders should redirect focus from centralized autonomous general intelligence to a plurality of…
The Turing Test Is Bad for Business
Originally posted on Wired: Written by Daron Acemoglu, Michael I. Jordan, and E. Glen Weyl on November 8, 2021 FEARS OF ARTIFICIAL intelligence fill the news: job losses, inequality, discrimination, misinformation, or even a superintelligence dominating the world. The one group everyone assumes will benefit is business, but the data seems to disagree. Amid all the hype, US businesses have been slow in adopting the most advanced AI technologies, and there is little evidence that such technologies are contributing significantly to productivity growth or job creation. This disappointing performance is not merely due to the relative immaturity of AI technology. It also comes from a fundamental mismatch between the needs of business and the way AI is currently being conceived by many in the technology…
Secure computation: Homomorphic encryption or hardware enclaves?
Originally posted on Medium: Written by Raluca Ada Popa on September 16, 2021 How to collaborate with confidential data without sharing it. Secure computation has become increasingly popular for protecting the privacy and integrity of data during computation. The reason is that it provides two tremendous advantages. The first advantage is that it offers “encryption in use” in addition to the already existing “encryption at rest” and “encryption in transit”. The “encryption in use” paradigm is important for security because “encryption at rest” protects that data only when it is in storage and “encryption in transit” protects the data only when it is being communicated over the network, but in both cases the data is exposed during computation, namely, while it…
So you want to build an open source tool/library as a grad student
This is a collection of experiences and recommendations for building an open source community as a grad student
Falx: Visualization by Example
https://falx.cs.washington.edu Falx makes visualization easy by synthesizing visualizations of the full dataset from small examples Modern visualization tools aim to let data analysts easily create exploratory visualizations. When the input data layout conforms to the visualization design, we can easily specify visualizations by mapping data columns to visual properties of the design. However, when there is a mismatch between data layout and the design, we need considerable effort on data transformation. But, if I am a novice data scientist without much programming experience, how can I create expressive visualizations? Falx is a visualization-by-example tool to address this challenge. Falx lets users demonstrate how a few data points should be visualized, and it automatically generalizes it into programs that can visualize…
We don’t need Data Engineers, we need better tools for Data Scientists
In most companies, Data Engineers support the Data Scientists in various ways. Often this means translating or productionizing the notebooks and scripts that a Data Scientist has written. A large portion of the Data Engineer’s role could be replaced with better tooling for Data Scientists, freeing Data Engineers to do more impactful (and scalable) work.
Using Ray as a foundation for a real-time analytic monitoring framework
Ray’s actor model, and its simplicity of implementation in Python-based frameworks is a primary motivation for using it in a higher-level research framework (Realm, to be published) for real-time analytic monitoring of critical events (e.g. suicide risk, infectious diseases, etc.) that my colleagues and I are working on. The purpose of Realm is to provide: real time alerts in response to, for example, continuously occurring, high-frequency clinical events, support for online learning, distribution of model updates through the hierarchy of models (local/embedded, regional, and central), and targeted, selective, and context-specific updates to these models. While other frameworks provide most of these functions (Akka, Spark, Kafka, etc.), we are exploring and using Ray because of its simplicity of implementation (using actors…
Ray Distributed AI Framework Curriculum Offered on the Intel® AI DevCloud
by Stephen Offer and Ellick Chan As a consequence of the growing computational demands of machine learning algorithms, the need for powerful computer clusters is increasing. However, existing infrastructure for implementing parallel machine learning algorithms is still primitive. While good solutions for specific use cases (e.g., parameter servers or hyperparameter search) and parallel data processing do exist (e.g., Hadoop or Spark), to parallelize machine learning algorithms, practitioners often end up building their own customized systems, leading to duplicated efforts. To help address this issue, the RISELab has created Ray, a high-performance distributed execution framework. Ray supports general purpose parallel and distributed Python applications and enables large-scale machine learning and reinforcement learning applications. It achieves scalability and fault tolerance by abstracting the…
Programming in Ray: Tips for first-time users
Ray is a general-purpose framework for programming a cluster. Ray enables developers to easily parallelize their Python applications or build new ones, and run them at any scale, from a laptop to a large cluster. Ray provides a highly flexible, yet minimalist and easy to use API. Table 1 shows the core of this API. In this blog, we describe several tips that can help first-time Ray users to avoid some common mistakes that can significantly hurt the performance of their programs. API Description Example ray.init() Initialize Ray context. @ray.remote Function or class decorator specifying that the function will be executed as a task or the class as an actor in a different process. @ray.remote @ray.remote def…
Modern Parallel and Distributed Python: A Quick Tutorial on Ray
Ray is an open source project for parallel and distributed Python. This article was originally posted here. Parallel and distributed computing are a staple of modern applications. We need to leverage multiple cores or multiple machines to speed up applications or to run them at a large scale. The infrastructure for crawling the web and responding to search queries are not single-threaded programs running on someone’s laptop but rather collections of services that communicate and interact with one another. This post will describe how to use Ray to easily build applications that can scale from your laptop to a large cluster. Why Ray? Many tutorials explain how to use Python’s multiprocessing module. Unfortunately the multiprocessing module is severely limited in…
Cloud Programming Simplified: A Berkeley View on Serverless Computing
David Patterson and Ion Stoica The publication of “Above the Clouds: A Berkeley View of Cloud Computing” on February 10, 2009 cleared up the considerable confusion about the new notion of “Cloud Computing.” The paper defined what Cloud Computing was, where it came from, why some were excited by it, what were its technical advantages, and what were the obstacles and research opportunities for it to become even more popular. More than 17,000 citations to this paper and an abridged version in CACM—with more than 1000 in the past year—document that it continues to shape the discussions and the evolution of Cloud Computing. “Cloud Programming Simplified: A Berkeley View on Serverless Computing” with some of the same authors commemorates the…
Scaling Interactive Pandas Workflows with Modin – Talk at PyData NYC 2018
In this talk, we will present Modin, a middle layer for DataFrames and interactive data science. Modin, formerly Pandas on Ray, is a library that allows users to speed up their Pandas workflows by changing a single line of code. During the presentation, we will discuss interesting ways Modin is being used, and show how we improve the performance of the most popular Pandas operations. Modin is an early-stage project at UC Berkeley’s RISELab designed to facilitate the use of distributed computing for Data Science. Often, a challenge encountered when trying to use tools for large-scale data is that there is a significant learning overhead. Modin is designed to expose a set of familiar APIs (Pandas, SQL, etc.) and internally…
Ray: Application-level scheduling with custom resources
Application-level scheduling with custom resources New to Ray? Start Here! Ray intends to be a universal framework for a wide range of machine learning applications. This includes distributed training, machine learning inference, data processing, latency-sensitive applications, and throughput-oriented applications. Each of these applications has different, and, at times, conflicting requirements for resource management. Ray intends to cater to all of them, as the newly emerging microkernel for distributed machine learning. In order to achieve that kind of generality, Ray enables explicit developer control with respect to the task and actor placement by using custom resources. In this blog post we are going to talk about use cases and provide examples. This article is intended for readers already familiar with…
What Is the Role of Machine Learning in Databases?
(This article was authored by Sanjay Krishnan, Zongheng Yang, Joe Hellerstein, and Ion Stoica.) What is the role of machine learning in the design and implementation of a modern database system? This question has sparked considerable recent introspection in the data management community, and the epicenter of this debate is the core database problem of query optimization, where the database system finds the best physical execution path for an SQL query. The au courant research direction, inspired by trends in Computer Vision, Natural Language Processing, and Robotics, is to apply deep learning; let the database learn the value of each execution strategy by executing different query plans repeatedly (an homage to Google’s robot “arm farm”) rather through a pre-programmed analytical…
A History of Postgres
(crossposted from databeta.wordpress.com) The ACM began commissioning a series of reminiscence books on Turing Award winners. Thanks to hard work by editor Michael Brodie, the first one is Mike Stonebraker’s book, which just came out. I was asked to write the chapter on Postgres. I was one of the large and distinguished crew of grad students on the Postgres project, so this was fun. ACM in its wisdom decided that these books would be published in a relatively traditional fashion—i.e. you have to pay for them. The publisher, Morgan-Claypool, has this tip for students and ACM members: Please note that the Bitly link goes to a landing page where Students, ACM Members, and Institutions who have access to the ACM…
An Overview of the CALM Theorem
For folks who care about what’s possible in distributed computing: Peter Alvaro and I wrote an introduction to the CALM Theorem and subsequent work that is now up on arXiv. The CALM Theorem formally characterizes the class of programs that can achieve distributed consistency without the use of coordination. — Joe Hellerstein (Cross-posted from databeta.wordpress.com.) I spent a good fraction of my academic life in the last decade working on a deeper understanding of how to program the cloud and other large-scale distributed systems. I was enormously lucky to collaborate with and learn from amazing friends over this period in the BOOM project, and see our work picked up and extended by new friends and colleagues. Our research was motivated by…
Confluo: Millisecond-level Queries on Large-scale Live Data
Confluo is a system for real-time distributed analysis of multiple data streams. Confluo simultaneously supports high throughput concurrent writes, online queries at millisecond timescales, and CPU-efficient ad-hoc queries via a combination of data structures carefully designed for the specialized case of multiple data streams, and an end-to-end optimized system design. We are excited to release Confluo as an open-source C++ project, comprising: Confluo’s data structure library, that supports high throughput ingestion of logs, along with a wide range of online (live aggregates, conditional trigger executions, etc.) and offline (ad-hoc filters, aggregates, etc.) queries, and, A Confluo server implementation, that encapsulates the data structures and exposes its operations via an RPC interface, along with client libraries in C++, Java and Python.…

An Open Source Tool for Scaling Multi-Agent Reinforcement Learning
We just rolled out general support for multi-agent reinforcement learning in Ray RLlib 0.6.0. This blog post is a brief tutorial on multi-agent RL and how we designed for it in RLlib. Our goal is to enable multi-agent RL across a range of use cases, from leveraging existing single-agent algorithms to training with custom algorithms at large scale.
Modin (Pandas on Ray) – October 2018
View the code on Gist.
SQL Query Optimization Meets Deep Reinforcement Learning
We show that deep reinforcement learning is successful at optimizing SQL joins, a problem studied for decades in the database community. Further, on large joins, we show that this technique executes up to 10x faster than classical dynamic programs and 10,000x faster than exhaustive enumeration. This blog post introduces the problem and summarizes our key technique; details can be found in our latest preprint, Learning to Optimize Join Queries With Deep Reinforcement Learning. SQL query optimization has been studied in the database community for almost 40 years, dating all the way back from System R’s classical dynamic programming approach. Central to query optimization is the problem of join ordering. Despite the problem’s rich history, there is still a continuous stream…
Going Fast and Cheap: How We Made Anna Autoscale
Background: In an earlier blog post, we described a system called Anna, which used a shared-nothing, thread-per-core architecture to achieve lightning-fast speeds by avoiding all coordination mechanisms. Anna also used lattice composition to enable a rich variety of coordination-free consistency levels. The first version of Anna blew existing in-memory KVSes out of the water: Anna is up to 700x faster than Masstree, an earlier state-of-the-art research KVS, and up to 800x faster than Intel’s “lock-free” TBB hash table. You can find the previous blog post here and the full paper here. We refer to that version of Anna as “Anna v0.” In this post, we describe how we extended the fastest KVS in the cloud to be extremely cost-efficient and…
Exploratory data analysis of genomic datasets using ADAM and Mango with Apache Spark on Amazon EMR (AWS Big Data Blog Repost)
Note: This blogpost is replicated from the AWS Big Data Blog and can be found here. As the cost of genomic sequencing has rapidly decreased, the amount of publicly available genomic data has soared over the past couple of years. New cohorts and studies have produced massive datasets consisting of over 100,000 individuals. Simultaneously, these datasets have been processed to extract genetic variation across populations, producing mass amounts of variation data for each cohort. In this era of big data, tools like Apache Spark have provided a user-friendly platform for batch processing of large datasets. However, to use such tools as a sufficient replacement to current bioinformatics pipelines, we need more accessible and comprehensive APIs for processing genomic data. We…
Implementing A Parameter Server in 15 Lines of Python with Ray
This blog post was originally posted here. View the code on Gist.
Pandas on Ray – Early Lessons from Parallelizing Pandas
View the code on Gist.
A Short History of Prediction-Serving Systems
Machine learning is an enabling technology that transforms data into solutions by extracting patterns that generalize to new data. Much of machine learning can be reduced to learning a model — a function that maps an input (e.g. a photo) to a prediction (e.g. objects in the photo). Once trained, these models can be used to make predictions on new inputs (e.g., new photos) and as part of more complex decisions (e.g., whether to promote a photo). While there are thousands of papers published each year on how to design and train models, there is surprisingly less research on how to manage and deploy such models once they are trained. It is this later, often overlooked, topic that we discuss…
The Right to not be Tracked II: in which I turn off the location permission for Google, but it tracks me anyway
I recently published a post about the blurry boundaries between standard system services and Google Maps on Android. I argued that these boundaries made it hard to talk about consent and competition around location services. However, the branching factor for the data sharing made the argument complex and hard to follow. Even as I was writing that post, in the train on the way into Berkeley, I started getting notifications from the Google app about the weather at my location. The Google app (aka Google Now) is a virtual assistant that is intended to provide context-sensitive helpful information to users. It is closed source, pre-installed, and it cannot be uninstalled or disabled. And I had already turned off all its…
The Right to not be Tracked: a Spotlight on Google Maps and Android Location Tracking
There has been a lot of interest in data collected about users by Facebook recently. Journalists have been shocked when they downloaded the data that Facebook has on them. Most of this concern has been focused around data collected through explicit user interaction such as web browsing, or clicking on “Like” and “Share” buttons. Background data collection, which occurs without any explicit user intervention, is arguably creepier, because it collects data whether or not you interact with the service. For example, Facebook has been criticized for logging texts and phone calls in the background. Facebook argues that users consented to sharing the data, although many users are still skeptical about how explicit the consent was. Similarly, Uber had to backtrack…
Michael I. Jordan: Artificial Intelligence — The Revolution Hasn’t Happened Yet
(This article has originally been published on Medium.com.) Artificial Intelligence (AI) is the mantra of the current era. The phrase is intoned by technologists, academicians, journalists and venture capitalists alike. As with many phrases that cross over from technical academic fields into general circulation, there is significant misunderstanding accompanying the use of the phrase. But this is not the classical case of the public not understanding the scientists — here the scientists are often as befuddled as the public. The idea that our era is somehow seeing the emergence of an intelligence in silicon that rivals our own entertains all of us — enthralling us and frightening us in equal measure. And, unfortunately, it distracts us. There is a different narrative that one can…
Open source platform + undergraduate energy = sustainability research
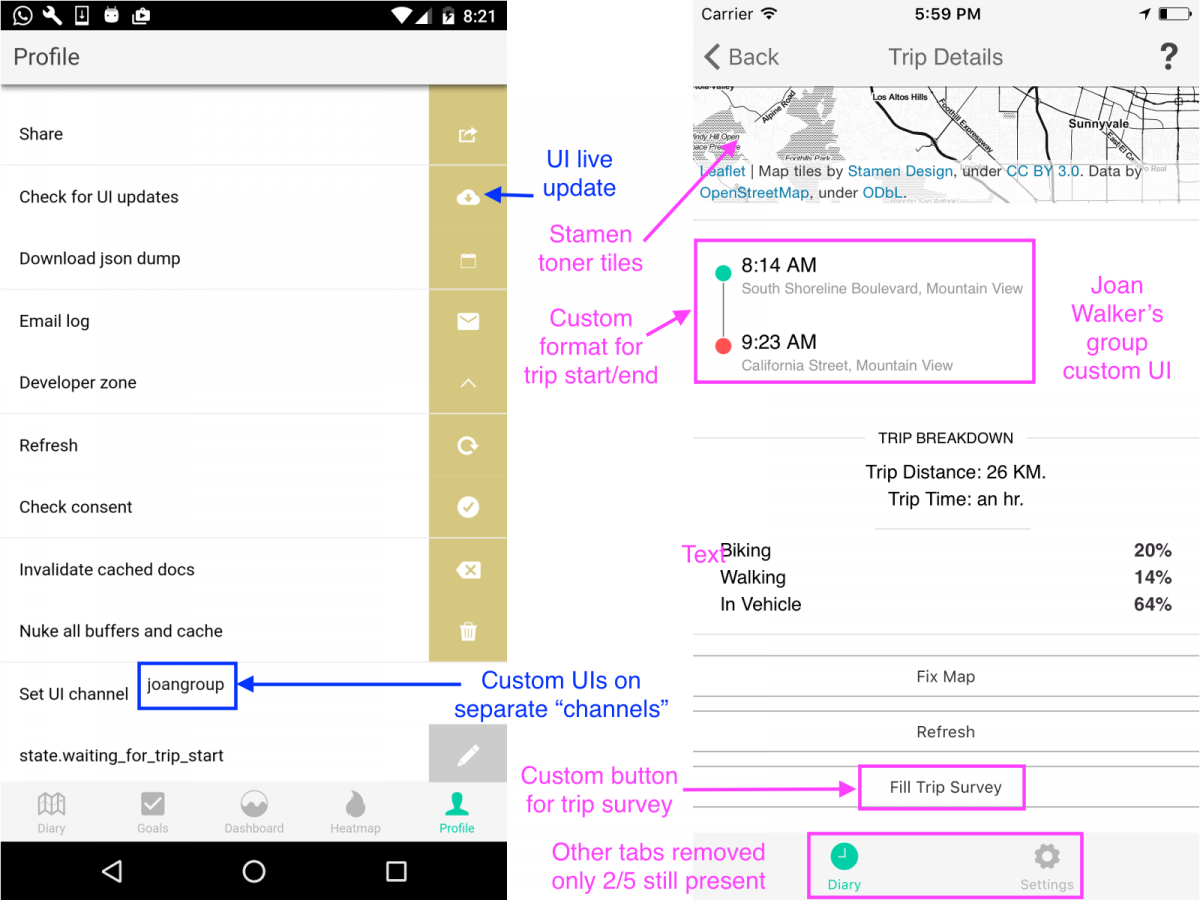
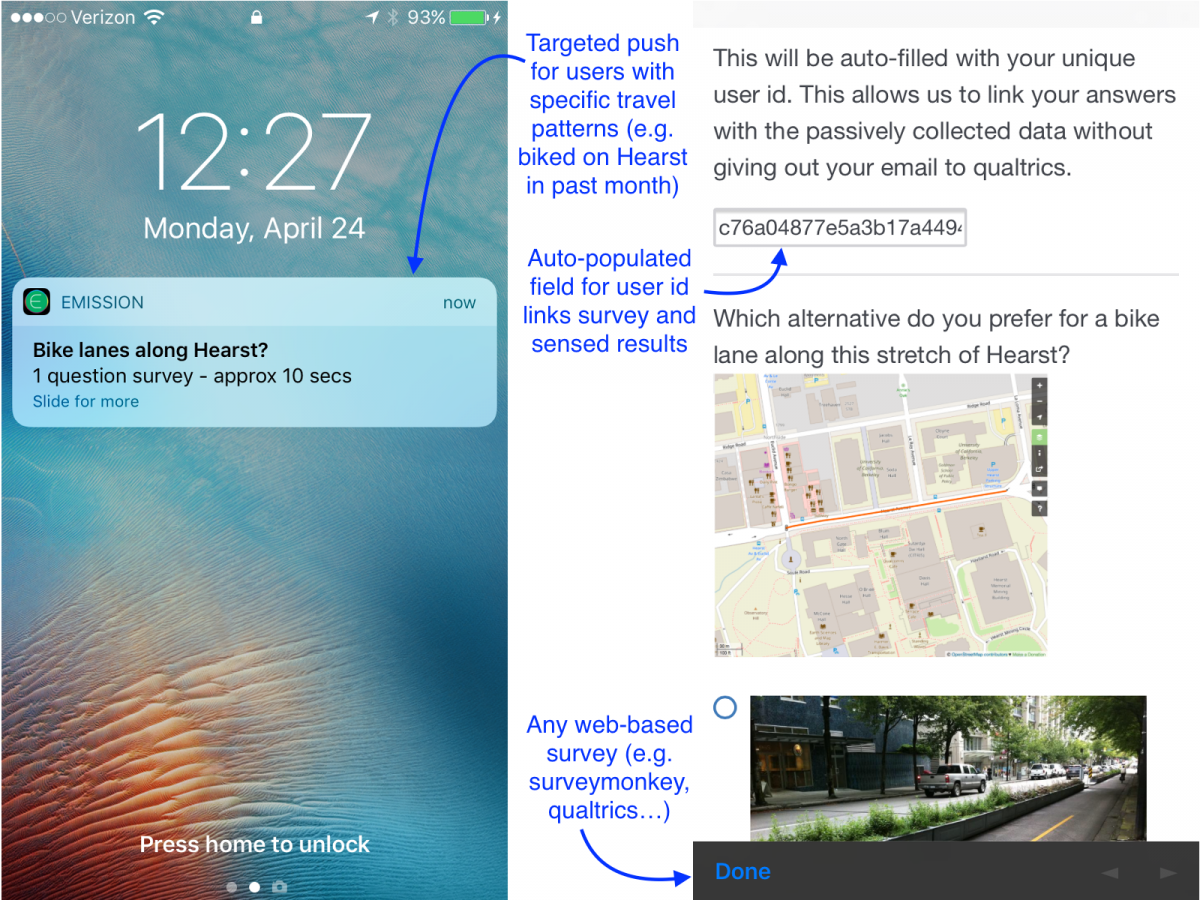
This Earth Day, join a study on motivating sustainable transportation behavior. I have blogged about the e-mission project earlier in the context of the National Transportation Data Challenge. (https://rise.cs.berkeley.edu/blog/making-cities-safer-data-collection-vision-zero/). To recap, e-mission focuses on building an extensible platform that can instrument the end-to-end multi-modal travel experience at the personal scale and collate it for analysis at the societal scale. In particular, it combines background data collection of trips, classified by modes, with user-reported incident data, and context-sensitive surveys. I also blogged earlier about involving undergraduates in research (https://amplab.cs.berkeley.edu/getting-a-dozen-20-year-olds-to-work-together-for-fun-and-social-good/). To recap, the challenges at the time included managing different skill levels, compressing the learn-plan-build cycle into one semester, and the fact that undergraduates typically don’t have the experience to build platform…
Online Foundations of Data Science Course Launches on edX!
UC Berkeley’s pathbreaking entry-level course on the Foundations of Data Science (Data 8) is launching on edX on April 2. This makes the fastest-growing class in UC Berkeley history available to everyone. Foundations of Data Science teaches computational and inferential thinking from the ground up. It covers everything from testing hypotheses, applying statistical inferences, visualizing distributions and drawing conclusions—all while coding in Python and using real world data sets. The course is taught by award-winning Berkeley professors and designed by a team of faculty working together across Berkeley’s Computer Science and Statistics Departments, led by RISE faculty Michael Jordan. The three 5-week online courses cover: Foundations of Data Science: Computational Thinking with Python, starting on April 2, teaches the basics…
Distributed Policy Optimizers for Scalable and Reproducible Deep RL
In this blog post we introduce Ray RLlib, an RL execution toolkit built on the Ray distributed execution framework. RLlib implements a collection of distributed policy optimizers that make it easy to use a variety of training strategies with existing reinforcement learning algorithms written in frameworks such as PyTorch, TensorFlow, and Theano. This enables complex architectures for RL training (e.g., Ape-X, IMPALA), to be implemented once and reused many times across different RL algorithms and libraries. We discuss in more detail the design and performance of policy optimizers in the RLlib paper. What’s next for RLlib In the near term we plan to continue building out RLlib’s set of policy optimizers and algorithms. Our aim is for RLlib to serve…
Anna: A Crazy Fast, Super-Scalable, Flexibly Consistent KVS 🗺
This article cross-posted from the DataBeta blog. There’s fast and there’s fast. This post is about Anna, a key/value database design from our team at Berkeley that’s got phenomenal speed and buttery smooth scaling, with an unprecedented range of consistency guarantees. Details are in our upcoming ICDE18 paper on Anna. Conventional wisdom (or at least Jeff Dean wisdom) says that you have to redesign your system every time you scale by 10x. As researchers, we asked the counter-cultural question: what would it take to build a key-value store that would excel across many orders of magnitude of scale, from a single multicore box to the global cloud? Turns out this kind of curiosity can lead to a system with pretty interesting practical…
Pandas on Ray
View the code on Gist.
RISECamp Behind the Scenes
RISECamp was held at UC Berkeley on September 7th and 8th. This post looks behind the scenes at the technical infrastructure used to provide a cloud-hosted cluster for each attendee with ready-to-use Jupyter notebooks requiring only a web browser to access. Background and Requirements RISECamp is the latest in a series of workshops held by RISELab (and its predecessor, AMPLab) showcasing the latest research from the lab. The sessions consist of talks on the latest research systems produced by the lab followed by tutorials and exercises for attendees to get hands-on practical experience using our latest technologies. In the past, attendees used their own laptops to perform the hands-on exercises, with each user setting up a local development environment and manually…
Fast Python Serialization with Ray and Apache Arrow
This post was originally posted here. Robert Nishihara and Philipp Moritz are graduate students in the RISElab at UC Berkeley. This post elaborates on the integration between Ray and Apache Arrow. The main problem this addresses is data serialization. From Wikipedia, serialization is … the process of translating data structures or object state into a format that can be stored … or transmitted … and reconstructed later (possibly in a different computer environment). Why is any translation necessary? Well, when you create a Python object, it may have pointers to other Python objects, and these objects are all allocated in different regions of memory, and all of this has to make sense when unpacked by another process on another machine. Serialization and deserialization…
Ray: 0.2 Release
This was originally posted on the Ray blog. We are pleased to announce the Ray 0.2 release. This release includes the following: substantial performance improvements to the Plasma object store an initial Jupyter notebook based web UI the start of a scalable reinforcement learning library fault tolerance for actors Plasma Since the last release, the Plasma object store has moved out of the Ray codebase and is now being developed as part of Apache Arrow (see the relevant documentation), so that it can be used as a standalone component by other projects to leverage high-performance shared memory. In addition, our Arrow-based serialization libraries have been moved into pyarrow (see the relevant documentation). In 0.2, we’ve increased the write throughput of the object store…
Low-Latency Model Serving with Clipper
The mission of the RISELab is to develop technologies that enable applications to make low-latency decisions on live data with strong security. One of the first steps towards achieving this goal is to study techniques to evaluate machine learning models and quickly render predictions. This missing piece of machine learning infrastructure, the prediction serving system, is critical to delivering real-time and intelligent applications and services. As we studied the prediction-serving problem, two key challenges emerged. The first challenge is supporting the stringent performance demands of interactive serving workloads. As machine learning models improve they are increasingly being applied in business critical settings and user-facing interactive applications. This requires models to render predictions that can meet the strict latency requirements of…
Opaque: Secure Apache Spark SQL
As enterprises move to cloud-based analytics, the risk of cloud security breaches poses a serious threat. Encrypting data at rest and in transit is a major first step. However, data must still be decrypted in memory for processing, exposing it to any attacker who can observe memory contents. This is a challenging problem because security usually implies a tradeoff between performance and functionality. Cryptographic approaches like fully homomorphic encryption provide full functionality to a system, but are extremely slow. Systems like CryptDB utilize lighter cryptographic primitives to provide a practical database, but are limited in functionality. Recent developments in trusted hardware enclaves (such as Intel SGX) provide a much needed alternative. These hardware enclaves provide hardware-enforced shielded execution that allows…
Announcing Ground v0.1
We’re excited to be releasing v0.1 of the Ground project! Ground is a data context service. It is a central repository for all the information surrounding the use of data in an organization. Ground concerns itself with what data an organization has, where that data is, who (both human beings and software systems) is touching that data, and how that data is being modified and described. Above all, Ground aims to be an open-source, vendor neutral system that provides users an unopinionated metamodel and set of APIs that allow them to think about and interact with data context generated in their organization. Ground has many use cases, but we’re focused on two specific ones at present: Data Inventory: large organizations…
Reinforcement Learning brings together RISELab and Berkeley DeepDrive for a joint mini-retreat
On May 2, RISELab and the Berkeley DeepDrive (BDD) lab held a joint, largely student-driven mini-retreat. The event was aimed at exploring research opportunities at the intersection of the BDD and RISE labs. The topical focus of the mini-retreat was emerging AI applications, such as Reinforcement Learning (RL), and computer systems to support such applications. Trevor Darrell kicked off the event with an introduction to the Berkeley DeepDrive lab, followed by Ion Stoica’s overview of RISE. The event offered a great opportunity for researchers from both labs to exchange ideas about their ongoing research activity and discover points of collaboration. Philipp Moritz started the first student talk session with an update on Ray — a distributed execution framework for emerging…
RISELab Announces 3 Open Source Releases
Part of the Berkeley tradition—and the RISELab mission—is to release open source software as part of our research agenda. Six months after launching the lab, we’re excited to announce initial v0.1 releases of three RISElab open-source systems: Clipper, Ground and Ray. Clipper is an open-source prediction-serving system. Clipper simplifies deploying models from a wide range of machine learning frameworks by exposing a common REST interface and automatically ensuring low-latency and high-throughput predictions. In the 0.1 release, we focused on reliable support for serving models trained in Spark and Scikit-Learn. In the next release we will be introducing support for TensorFlow and Caffe2 as well as online-personalization and multi-armed bandits. We are providing active support for early users and will be following Github issues…
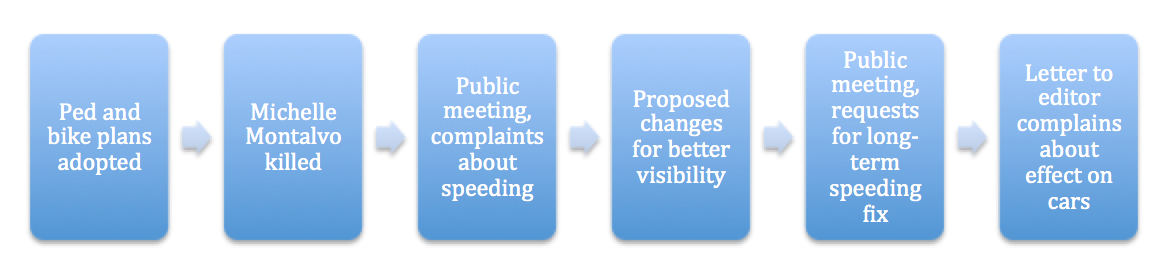
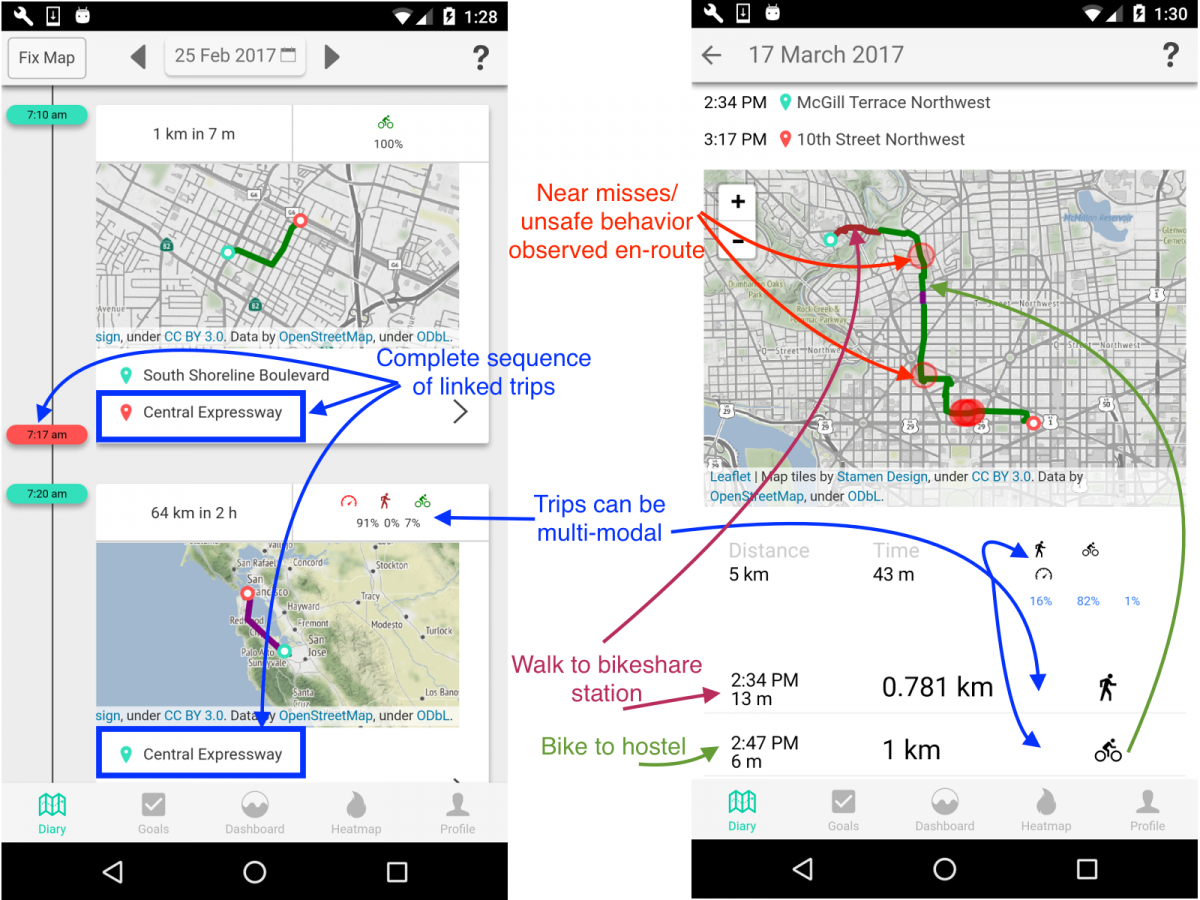
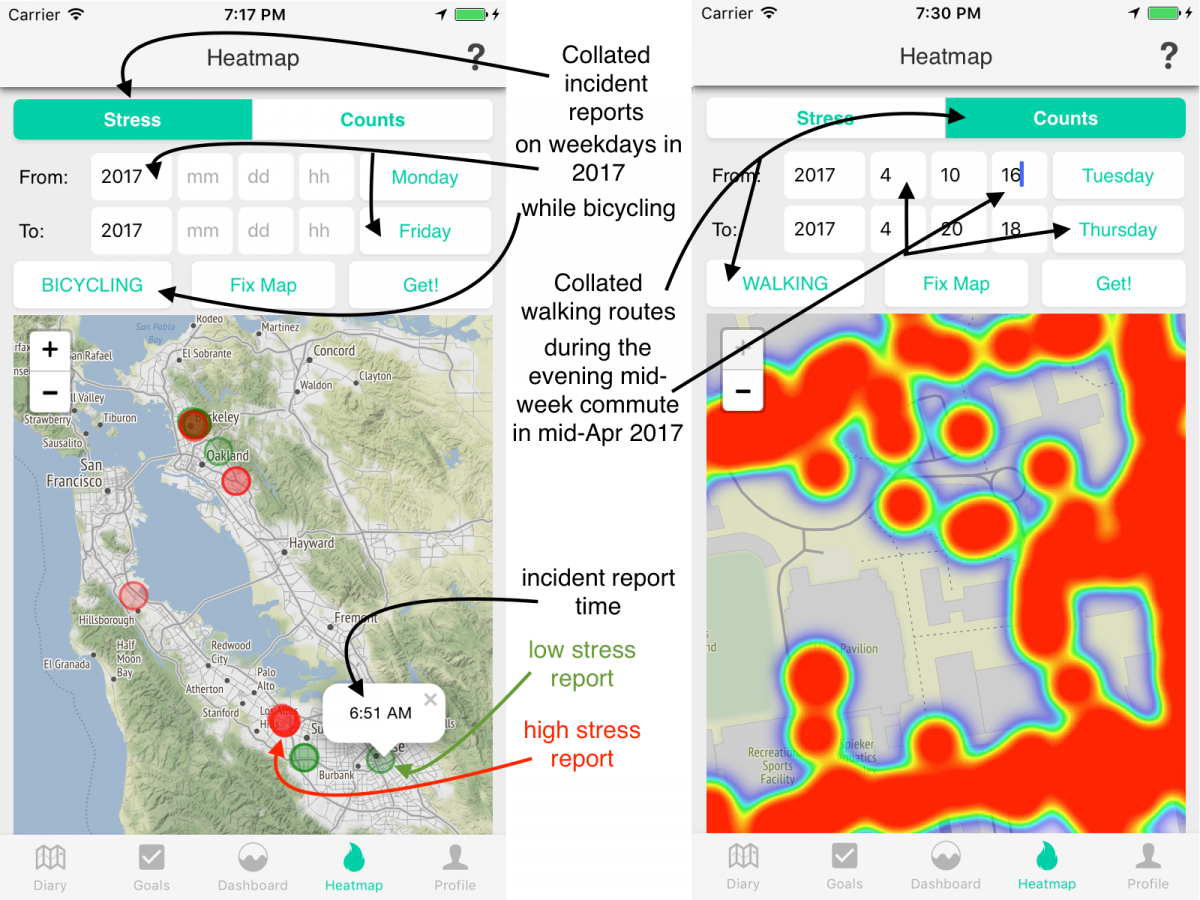
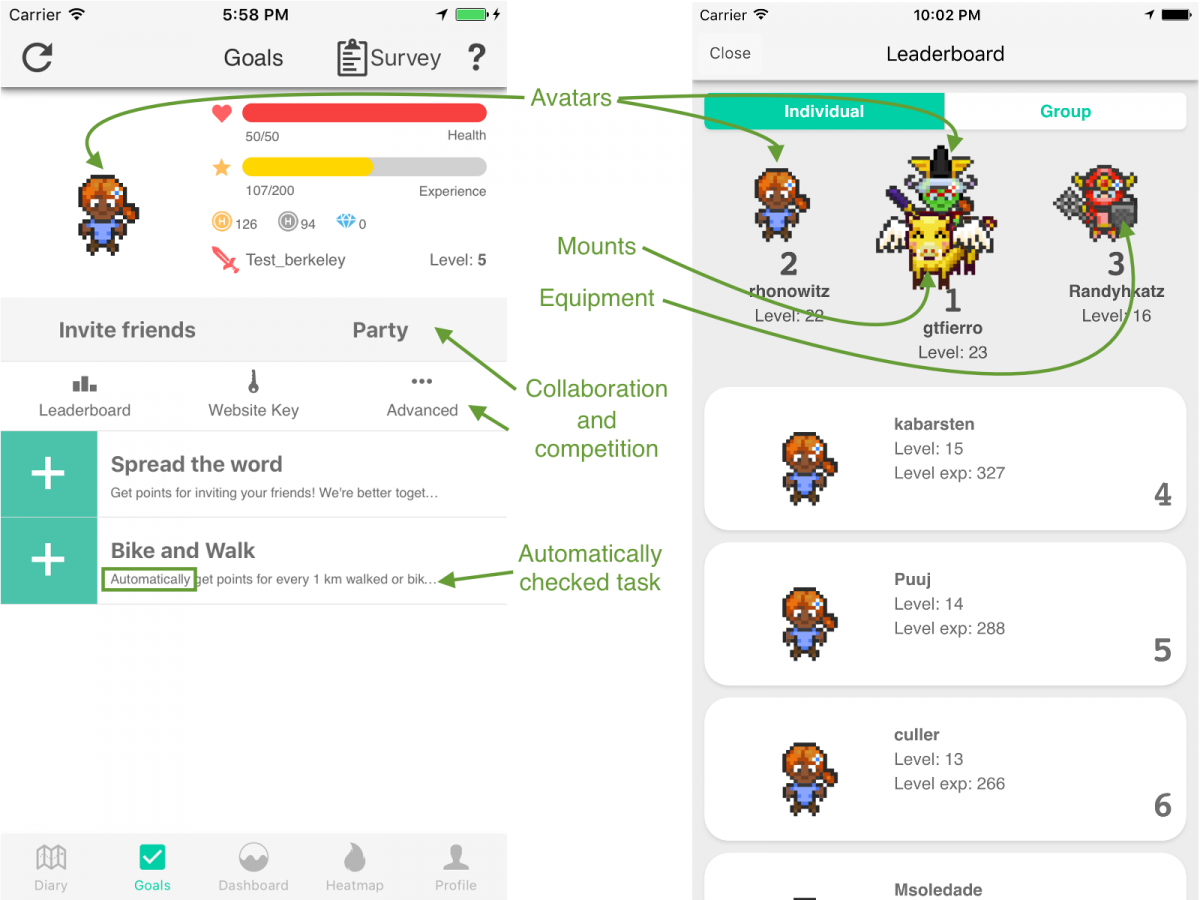
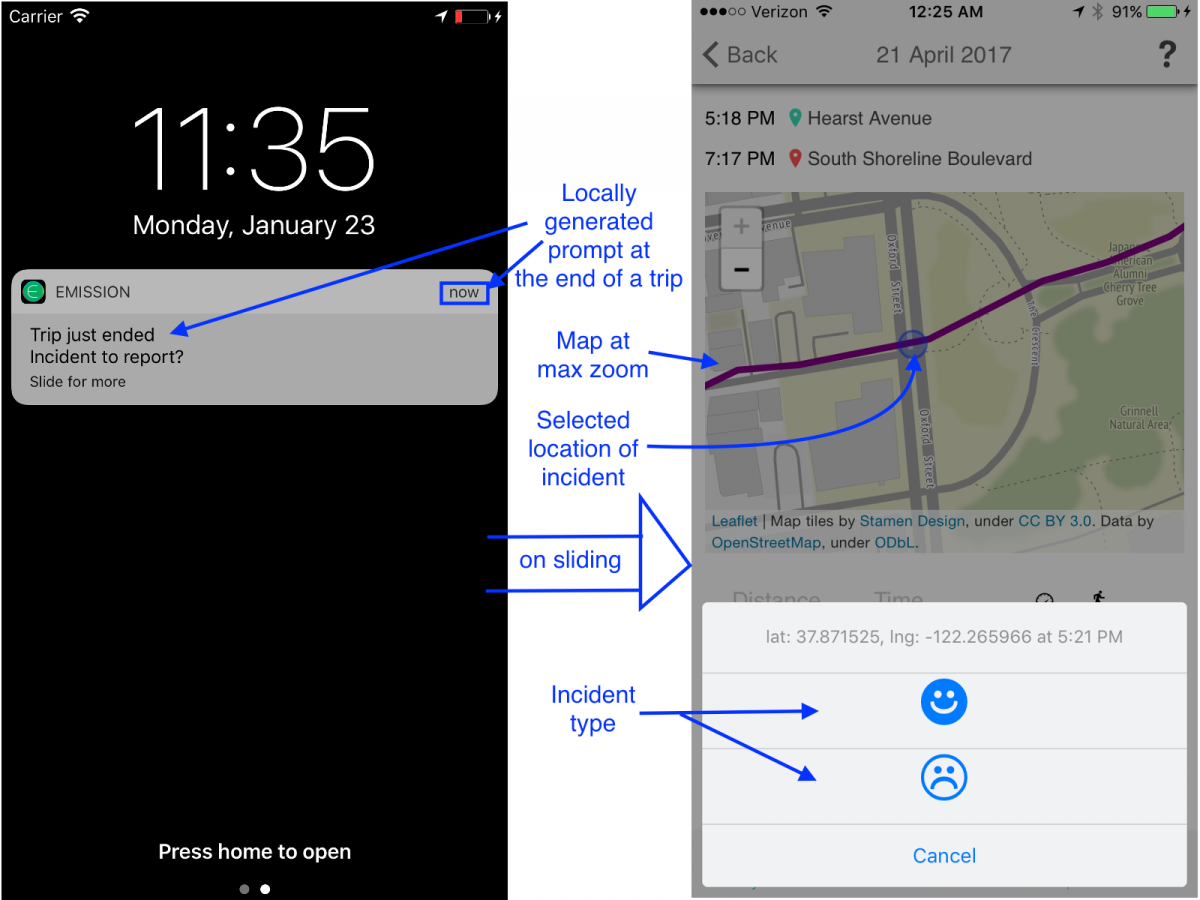
Making cities safer: data collection for Vision Zero
A critical part of enabling cities to implement their Vision Zero policies – the goal of the current National Transportation Data Challenge – is to be able to generate open, multi-modal travel experience data. While existing datasets use police and hospital reports to provide a comprehensive picture of fatalities and life altering injuries, by their nature, they are sparse and resist use for prediction and prioritization. Further, changes to infrastructure to support Vision Zero policies frequently require balancing competing needs from different constituencies – protected bike lanes, dedicated signals and expanded sidewalks all raise concerns that automobile traffic will be severely impacted. A timeline of the El Monte/Marich intersection in Mountain View, from 2014 to 2017 provides an opportunity to…
Declarative Heterogeneity Handling for Datacenter and ML Resources
Challenge Heterogeneity in datacenter resources has become the fact of life. We identify and categorize a number of different types of heterogeneity. When talking about heterogeneity, we generally refer to static or dynamic attributes associated with individual resources. Previously the levels of heterogeneity were fairly benign and limited to a few different types of processor architectures. Now, however, it has become a common trend to deploy hardware accelerators (e.g., Tesla K40/K80, Google TPU, Intel Xeon PHI) and even FPGAs (e.g., Microsoft Catapult project). Nodes themselves are connected with heterogeneous interconnects, oftentimes with more than one interconnect option available (e.g., 40Gbps ethernet backbone, Infiniband, FPGA torus topology). The workloads we consolidate on top of this diverse hardware differ vastly in their success metrics (completion…
RISELab at Spark Summit
This year, Spark Summit East was held in Boston between February 7-9. With over 1,500 attendees, this was the largest Spark Summit ever outside the Bay Area. Apache Spark, developed in large at AMPLab (the precursor of RISELab), is now the de-facto standard of big data processing. Like the previous Spark summits, UC Berkeley had a very strong presence. Ion Stoica gave a keynote on RISELab, describing the lab’s research focus on addressing a long-standing grand challenge in computing: enable machines to act autonomously and intelligently, to rapidly and repeatedly take appropriate actions based on information in the world around them. The presentation also discussed some early results from two recent projects, Drizzle and Opaque, which had their own presentations…
Serverless Scientific Computing
For many scientific and engineering users, cloud infrastructure remains challenging to use. While many of their use cases are embarrassingly parallel, the challenges involved in provisioning and using stateful cloud services keep them trapped on their laptops or large shared workstations. Before getting started, a new cloud user confronts a bewildering number of choices. First, what instance type do they need ? How do they make the compute/memory tradeoff? How large do they want their cluster to be? Can they take advantage of dynamic market-based instances (spot instances) that can disappear at any time? What if they have 1000 small jobs, each of which takes a few minutes — what’s the most cost-effective way of allocating servers? What host operating…
Metadata Megafail: Messing up Your Data Strategy in 3 Easy Steps
A key aspect of the RISELab agenda is to aggressively harness data—lots of it, both historical and live. Of course bits in computers don’t provide value on their own. We need a broader context for data: where it came from, what it represents, and how it gets used. Traditionally, people called this metadata: the data about our data. Requirements for metadata have changed drastically in recent years in response to technology trends. There’s an emerging groundswell to address these new requirements and explore new opportunities. This includes our work on the broader notion of data context in the Ground system. How should data-driven organizations respond to these changing requirements? In the tradition of Berkeley advice like how to build a bad research center and…
RISELab Kicks Off
Berkeley’s computer science division has an ongoing tradition of 5-year collaborative research labs. In the fall of 2016 we closed out the most recent of the series: the AMPLab. We think it was a pretty big deal, and many agreed. One great thing about Berkeley is the endless supply of energy and ideas that flows through the place — always bringing changes, building on what came before. In that spirit, we’re fired up to announce the Berkeley RISELab, where we will focus intensely for five years on systems that provide Real-time Intelligence with Secure Execution. Context RISELab represents the next chapter in the ongoing story of data-intensive systems at Berkeley; a proactive step to move beyond Big Data analytics into…