Challenge
Heterogeneity in datacenter resources has become the fact of life. We identify and categorize a number of different types of heterogeneity. When talking about heterogeneity, we generally refer to static or dynamic attributes associated with individual resources. Previously the levels of heterogeneity were fairly benign and limited to a few different types of processor architectures. Now, however, it has become a common trend to deploy hardware accelerators (e.g., Tesla K40/K80, Google TPU, Intel Xeon PHI) and even FPGAs (e.g., Microsoft Catapult project). Nodes themselves are connected with heterogeneous interconnects, oftentimes with more than one interconnect option available (e.g., 40Gbps ethernet backbone, Infiniband, FPGA torus topology).
The workloads we consolidate on top of this diverse hardware differ vastly in their success metrics (completion time, SLO attainment, high availability) and are increasingly able to run on different configurations of resources (e.g., with/without hardware acceleration, with/without the dedicated low-latency interconnect, same rack vs. cross-rack) with correspondingly different run times associated with those placement options. The question becomes, how do you allocate the right sets of resources to the right jobs at the right time?
Research
We proposed a scheduling algebra that allows to express spatio-temporal placement preferences succinctly and a compilation algorithm for resource requests expressed with this scheduling algebra that automatically translates them into Mixed Integer Linear Programming (MILP) problems, solved with an off-the-shelf solver online to schedule continuously arriving jobs. The following diagram gives a high-level overview of the end-to-end architecture we’ve built to instantiate these ideas.
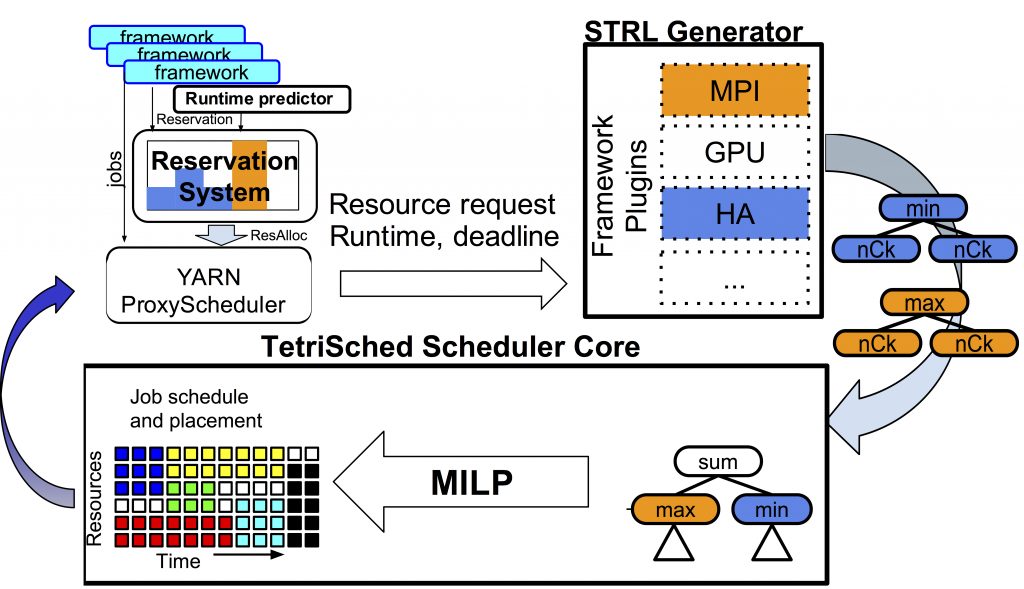
TetriSched Architecture Diagram
Resource requests for jobs of different types are translated into our Space-Time Resource Language (STRL) expressions that declaratively and succinctly capture jobs’ resource preferences. Each “n Choose k” (nCk) primitive, fundamentally, is able to map any k-subset of resources chosen from a specified resource equivalence set to a scalar value in R. STRL expressions are functions that map a resource superset to R, and does so in a very succinct form of algebraic expressions. These nCk primitives and, more generally, any subexpressions expressed in STRL can then be composed, much like algebraic expressions. STRL defines a handful of operators, such as max, min, sum, scale, and barrier that behave intuitively, as they evaluate to the max-valued subexpression, min-valued subexpression, to the sum of all operand values, scale the value of a single operand, or threshold the value signal by evaluating to the specified threshold, if reached, and zero otherwise.
A given resource request, thus translated, can then be aggregated with other pending requests in the scheduler core. During each scheduling epoch, the aggregate STRL expression, representing all outstanding resource demand, is then translated to a canonical Mixed Integer Linear Programming problem instance and solved on-line to produce a schedule within a few seconds. The result of this solution dictates which jobs get which resources right now and are communicated to the resource manager we integrate with.
Ongoing Work
Note that this scheduling algebra treats resources as abstract entities that can be represented with a set of (key, value) attribute pairs. As such, it holds promise to be generally applicable to a wider class of application domains, specifically, Machine Learning. As ML continues to gain popularity in mainstream business analytics, the number of models that could serve the same set of application queries continues to grow. This leads to the rise of ML model heterogeneity. Our ongoing work extends STRL to handle heterogeneous ML models for multi-model inference serving in a multi-tenant environment.
For a much more detailed treatment of the subject of resource heterogeneity, please refer to the TetriSched EuroSys’16 paper or my website.
— Alexey Tumanov