In this blog post we introduce Ray RLlib, an RL execution toolkit built on the Ray distributed execution framework. RLlib implements a collection of distributed policy optimizers that make it easy to use a variety of training strategies with existing reinforcement learning algorithms written in frameworks such as PyTorch, TensorFlow, and Theano. This enables complex architectures for RL training (e.g., Ape-X, IMPALA), to be implemented once and reused many times across different RL algorithms and libraries.
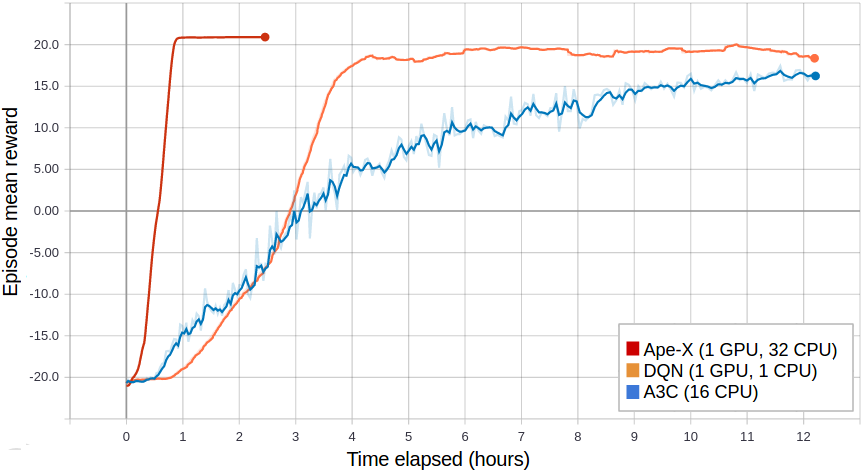
Figure 1: Reproduction of the Ape-X distributed prioritization algorithm using 32 actors in RLlib (red) converges more quickly than vanilla DQN (orange) and A3C (blue) when training PongNoFrameskip-v4. Existing RL algorithms can use RLlib’s distributed Ape-X optimizer by extending a common policy evaluation interface. Code to reproduce can be found here.
Proposal: A separation of concerns
While there has been significant progress in portable abstractions for deep learning (e.g., ONNX), in the absence of a single dominant computational pattern for reinforcement learning (i.e., tensor algebra), there has been comparatively less progress in abstractions specifically targeting RL. Today there are many existing open-source RL libraries, each typically specialized for a particular deep learning framework (e.g., PyTorch). As a consequence, these RL algorithms are tightly coupled with particular parallel execution strategies (e.g., built with distributed TensorFlow, MPI), limiting code reuse and reproducibility between libraries.
We propose a practical pattern for organizing RL algorithms to improve code reuse and reproducibility. At a high level, we decouple the algorithm “data plane” from the “control plane”, that is, the subroutines used to generate samples and update policies are separated from the control logic that determines when to invoke these subroutines.
To see why this helps, consider the family of algorithms for Deep Q-Networks (DQN), which includes several formulations including the original formulation, asynchronous DQN, and Ape-X. In Figure 2(a) below, we categorize the vanilla DQN pseudocode into lines for control logic (orange), sampling (green), replay (violet), and gradient-based optimization (blue). In Figure 2(b), the Ape-X formulation of distributed DQN, these same components are still used, but are organized quite differently. Even though the model and loss may be exactly the same in Ape-X, in the practical setting it is often quite hard to reuse DQN code due to the tight coupling of the policy model and loss definitions and the control logic for training.


Ideally, authors should be able to take an existing single-threaded DQN implementation and just “swap in” the asynchronous or Ape-X distributed training strategies for comparison. This can be done by pulling out a policy optimizer component that is responsible for executing the training strategy given definitions of the model, loss, and sampling subroutines specific to DQN.
Policy Optimizer abstraction
Let’s look at what DQN would look like if we were to use the policy optimizer abstraction:
- The algorithm author would implement a policy evaluator class (Figure 3) that defines how to sample experiences from the policy, compute gradients from experiences, apply gradients, and get/set policy weights.
- Since the class encapsulates all neural net interactions, any deep learning framework can be used to define the methods.
- Evaluators hold a copy of the policy parameters and can be replicated in multiple processes for parallelism.
- The author then can implement or use an existing policy optimizer class (Table 1) to coordinate execution between one or more replicas of the policy evaluator class.
- The author initializes the policy optimizer with the evaluator class and calls optimizer.step() repeatedly to run multiple rounds of training.
- Between policy optimizer steps, the author can use the training statistics to decide whether to update the DQN target network, report progress to the console, or make control decisions (e.g., checkpoint or stop training).
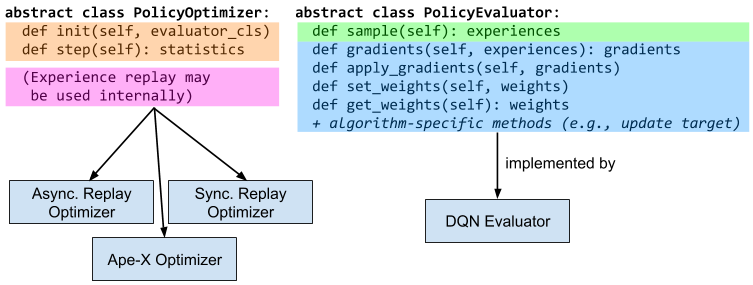
Figure 3: RLlib’s policy optimizer abstraction simplifies implementation of e.g., DQNs. Algorithm authors can pick among several policy optimizer implementations once they implement the policy evaluator interface for DQN.
RLlib implements several policy optimizers that we use as a basis for RLlib’s reference algorithms, which include DQN, Ape-X DQN, A3C, ES, and PPO. These policy optimizers are built on top of the Ray distributed execution framework for scalability, though we note that policy optimizers can be implemented with other parallelism frameworks as well. The following table summarizes RLlib’s current policy optimizers:
| Policy optimizer class | Operating range | Works with | Description |
| AsyncOptimizer | 1-10s of CPUs | (all) | Asynchronous gradient-based optimization e.g., for A3C |
| LocalSyncOptimizer | 0-1 GPU + 1-100s of CPUs | (all) | Synchronous gradient-based optimization with parallel sample collection |
| LocalSyncReplayOptimizer | 0-1 GPU + 1-100s of CPUs | Off-policy algorithms | Adds a replay buffer to LocalSyncOptimizer |
| LocalMultiGPUOptimizer | 0-10 GPUs + 1-100s of CPUs | Algorithms written in TensorFlow | Implements data-parallel optimization over multiple local GPUs, e.g., for PPO |
| ApexOptimizer | 1 GPU + 10-100s of CPUs | Off-policy algorithms w/ sample prioritization | Implements the Ape-X distributed prioritized experience replay algorithm for DQN / DDPG |
Scaling existing algorithms with RLlib policy optimizers
Though RLlib provides several built-in algorithms, our long-term goal is to provide a platform for the scalable execution and evaluation of other RL libraries, in a framework-agnostic way. It is already possible to leverage RLlib’s policy optimizers today.
As examples, we have ported a PyTorch implementation of Rainbow to use RLlib policy optimizers, and also the Baselines DQN implementation (note that the performance of these examples have not been tested). This was done by taking their existing training loop code and splitting it into subroutines for sampling and gradient optimization. Since these algorithms already had similar abstractions for code organization purposes, we found the changes to be straightforward. You can find links to the code below:
- PyTorch Rainbow integration example
- original code
- our branch
- RainbowEvaluator class
- simple training loop using optimizer.step()
- full RLlib agent with Ray Tune script for running locally and with Ape-X
- Baselines DQN integration example
- original code
- our branch
- BaselinesDQNEvaluator class
- simple training loop using optimizer.step()
- full RLlib agent with Ray Tune script for running locally and with Ape-X
In general we expect that any gradient-based algorithm can be ported to RLlib with less than half an hour of work. Once done, this enables any of RLlib’s built-in policy optimizers to be used. It also enables integration with other libraries such as Ray Tune, which makes it easy to run concurrent experiments with algorithms such as Population Based Training.
Performance
Policy optimizers can execute training in a highly performant and scalable way. The Ape-X RLlib policy optimizer (Figures 1 and 4) achieves comparable learner throughput (~8.5k frames/s on a V100 GPU), and a higher sampling throughput (>100k environment frames/s with 256 workers) compared to the reference results.
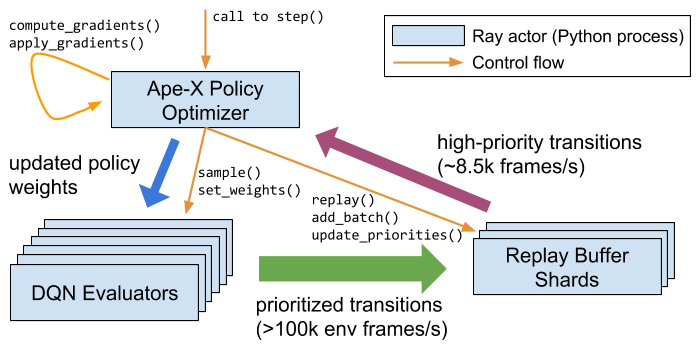
Figure 4: The Ape-X policy optimizer can achieve very high data throughputs. This is possible since the Ray object store permits the bulk of the data to be passed directly between workers and for data transfers to occur through shared memory for co-located processes.
We discuss in more detail the design and performance of policy optimizers in the RLlib paper.
What’s next for RLlib
In the near term we plan to continue building out RLlib’s set of policy optimizers and algorithms. Our aim is for RLlib to serve as a common toolkit of scalable execution strategies for RL, and as such will focus on the performance and distributed execution aspects.
We’re also working with other projects using RLlib:
- The Flow project is using RLlib for large-scale traffic control experiments. They are extending RLlib’s algorithms to include multi-agent support. This will enable studying the potential benefits of using automated vehicles to mitigate highway congestion.
- Our research partners at Ericsson are leveraging RLlib’s scalability to study the dynamic control of cellular antennas in urban areas, improving aggregate user bandwidth and latency. RLlib’s support for distributed execution is critical since high-fidelity industrial simulators can be very compute intensive.
If you’re interested in using or contributing to Ray RLlib, you can find us on GitHub or the ray-dev mailing list.
Code: https://github.com/ray-project/ray/tree/master/python/ray/rllib
Docs: http://ray.readthedocs.io/en/latest/rllib.html