by Stephen Offer and Ellick Chan
As a consequence of the growing computational demands of machine learning algorithms, the need for powerful computer clusters is increasing. However, existing infrastructure for implementing parallel machine learning algorithms is still primitive. While good solutions for specific use cases (e.g., parameter servers or hyperparameter search) and parallel data processing do exist (e.g., Hadoop or Spark), to parallelize machine learning algorithms, practitioners often end up building their own customized systems, leading to duplicated efforts.
To help address this issue, the RISELab has created Ray, a high-performance distributed execution framework. Ray supports general purpose parallel and distributed Python applications and enables large-scale machine learning and reinforcement learning applications. It achieves scalability and fault tolerance by abstracting the control state of the system in a global control store and keeping all other components stateless. It uses a shared-memory distributed object store to efficiently handle large data through shared memory, and it uses a bottom-up distributed scheduling architecture to achieve low-latency and high-throughput scheduling. It uses a lightweight API based on dynamic task graphs and actors to express a wide range of applications in a flexible manner.
The Intel® AI Academy is working with the RISELab to offer the power of distributed AI to research universities across the world by providing training materials on Ray. Another resource for Ray training is the Intel AI DevCloud, a free academic cloud compute service designed for AI workloads. Using the DevCloud, AI researchers and students can spin up compute nodes running Ray to build sophisticated distributed AI models using state-of-the art algorithms for distributed training and distributed reinforcement learning.
To promote the use of Ray on DevCloud in classrooms, we have divided the training materials created by the Ray team into eight individual hour-long tutorials. We hope this will allow professors from around the world to adopt this cutting-edge technology. The material covers not only how to use and optimize distributed workloads with Ray, but also covers Tune, a hyperparameter optimization library; RLlib, a reinforcement learning library; and Modin, which parallelizes the popular Pandas library. Professors can select the level of depth appropriate for their classroom, which can vary from introductory lectures to advanced topics.
Intel AI DevCloud
While one of the main benefits of Ray* is the ease of scaling an application from a laptop to a datacenter, running a Ray application at scale is still an expensive proposition. Furthermore, many users do not have access to a computing cluster. To help alleviate this problem, Intel® has been working to support Ray* on the Intel® AI DevCloud, a free AI cloud infrastructure, also available through the AI Academy.
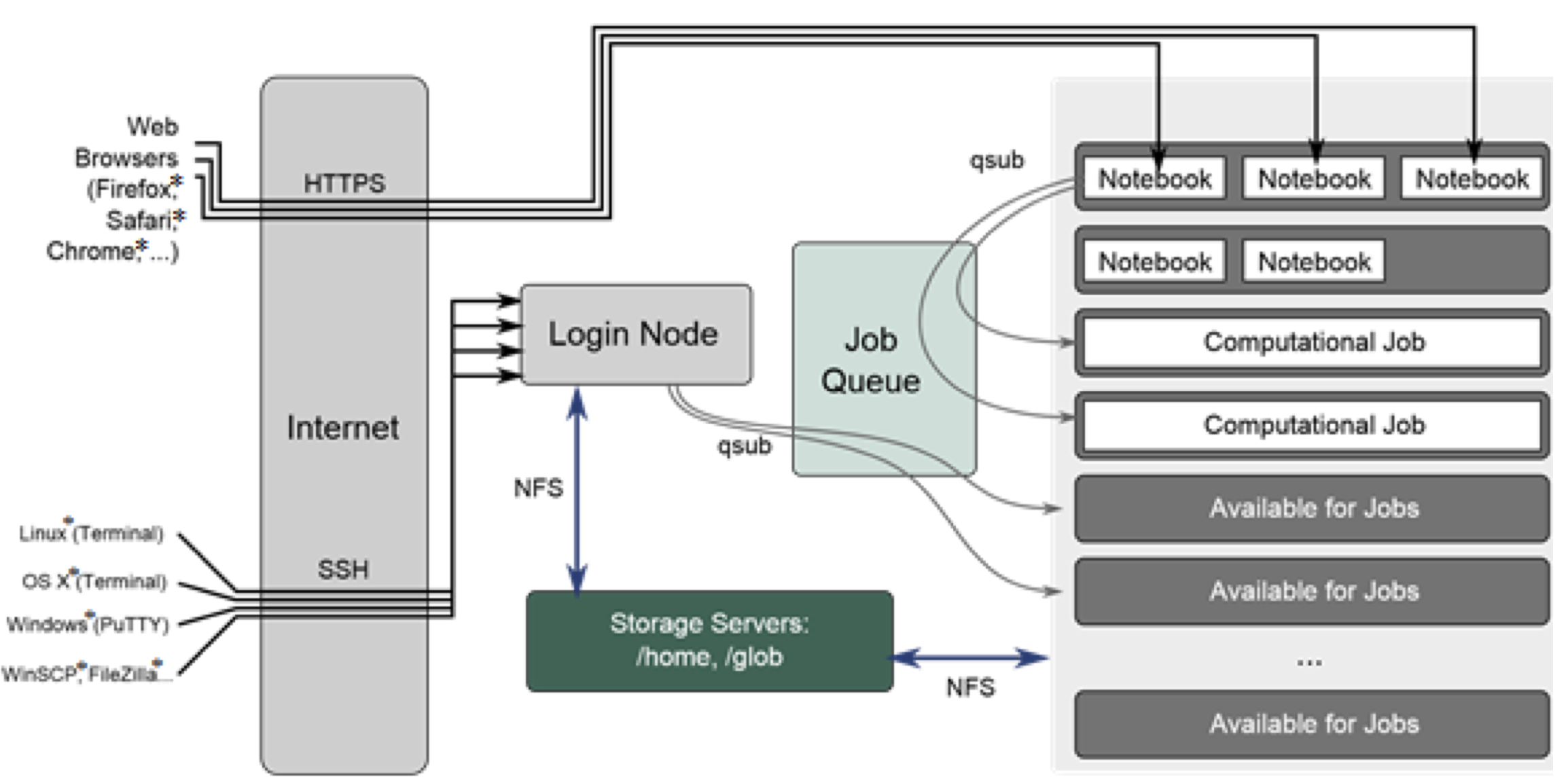
The system architecture of the DevCloud, as shown in the diagram above, is a High Performance Computing (HPC) cluster that can be accessed via a single login node. This node can be used to submit jobs to the cluster using PBS (Portable Batch System) commands. A command consists essentially of a bash script that also specifies the resource allocation for the job, such as the number of nodes, the per-node memory, and walltime.
Getting Started with Ray on the DevCloud
To try Ray on the DevCloud, apply for a free 30-day account here. For professors doing research or teaching, please reach out for extended access here. Once access has been granted, please clone this git repository for access to sample code.
To run this example on DevCloud, execute the following commands after entering an interactive session:
ray start --head echo “” >> head_ip python py_create_workers.py 5 python a2c_train.py
The rest of this section describes how the sample code works and how the PBS batch system works with Ray.
As an example, the following PBS script calls 1 node with an hour of walltime and 32 GB of memory:
#!/bin/bash #PBS –l nodes=1:ppn=2 #PBS –l walltime=01:00:00 #PBS –l mem=32gb source activate my_env python my_job.py
Installing packages on the DevCloud
One difference when installing packages through Pip on DevCloud is that it requires the –user flag due to the file system permission levels for non-admin users. As a side note, DevCloud is set up to use Conda environments and is the recommended way of keeping package dependencies clean whenever installing new libraries. To install Ray from PyPI, run the following command:

Starting a Ray job on the DevCloud
To call a Ray worker with the default settings of one node and 96 GB of RAM, the following script can be written in a file named create_worker. The call to sleep is to keep the worker on for one hour, otherwise it will start the worker, but then immediately quit.
ray start --redis-address 10.5.9.7:16884 sleep 3600
Instead of having to call qsub create_worker multiple times, it can be automated in Python with a file named py_create_workers.py. The command qsub is used to submit the PBS script to the job queue. Note that instead of calling os.system(“qsub create_worker”), it is the full file path of qsub since the system paths cannot find qsub while in interactive mode due to the system paths for the compute nodes.
import sys
import os
for i in range(int(sys.argv[1])):
os.system('/usr/local/bin/qsub create_worker')
In order to make sure that the other nodes are connected to the head node, the following script named get_ip_addresses.py can be used to check the number of nodes. Note that there will be six in this example since there are five worker nodes and one head node. DevCloud currently only allows up to five running jobs per user through the qsub queueing system, giving a user access to a total of 144 CPUs and 576 GB of RAM.
import ray
import time
import sys
import os
ray.init(redis_address="10.5.9.7:16884")
@ray.remote
def f():
time.sleep(0.01)
return ray.services.get_node_ip_address()
while True:
ips = set(ray.get([f.remote() for _ in range(1000)]))
print(ips)
print(len(ips))
time.sleep(1)
Running an RL workload
An A2C agent can be trained to learn SpaceInvaders using the Python RLlib API in a script called a2c_train.py. The default hardware configuration has to be changed since there are no GPUs on DevCloud, and RLlib typically has a GPU on the training node while the other CPU nodes are performing rollouts.
import ray
import ray.rllib.agents.a3c as a3c
from ray.tune.logger import pretty_print
ray.init(redis_address="10.5.9.7:16884")
config = a3c.DEFAULT_CONFIG.copy()
config["num_gpus"] = 0
config["num_gpus_per_worker"] = 0
config["num_workers"] = 5
agent = a3c.A2CAgent(config=config, env="SpaceInvadersNoFrameskip-v4")
for i in range(1000):
result = agent.train()
print(pretty_print(result))
if i % 100 == 0:
checkpoint = agent.save()
print("checkpoint saved at", checkpoint)
Before calling ray start, an interactive session has to be started because workloads cannot be run on the login node. Running qsub –I –lselect=1 will call up an interactive job on one compute node. Notice that it will say that it is on node c009-n003 or another similar node id instead of just the login node, meaning that it has moved from the login node to a compute node.

Now that a compute node is being used, the head node can be established on this new node. Remember to use the same IP address that is in the output when connecting workers to this head node.
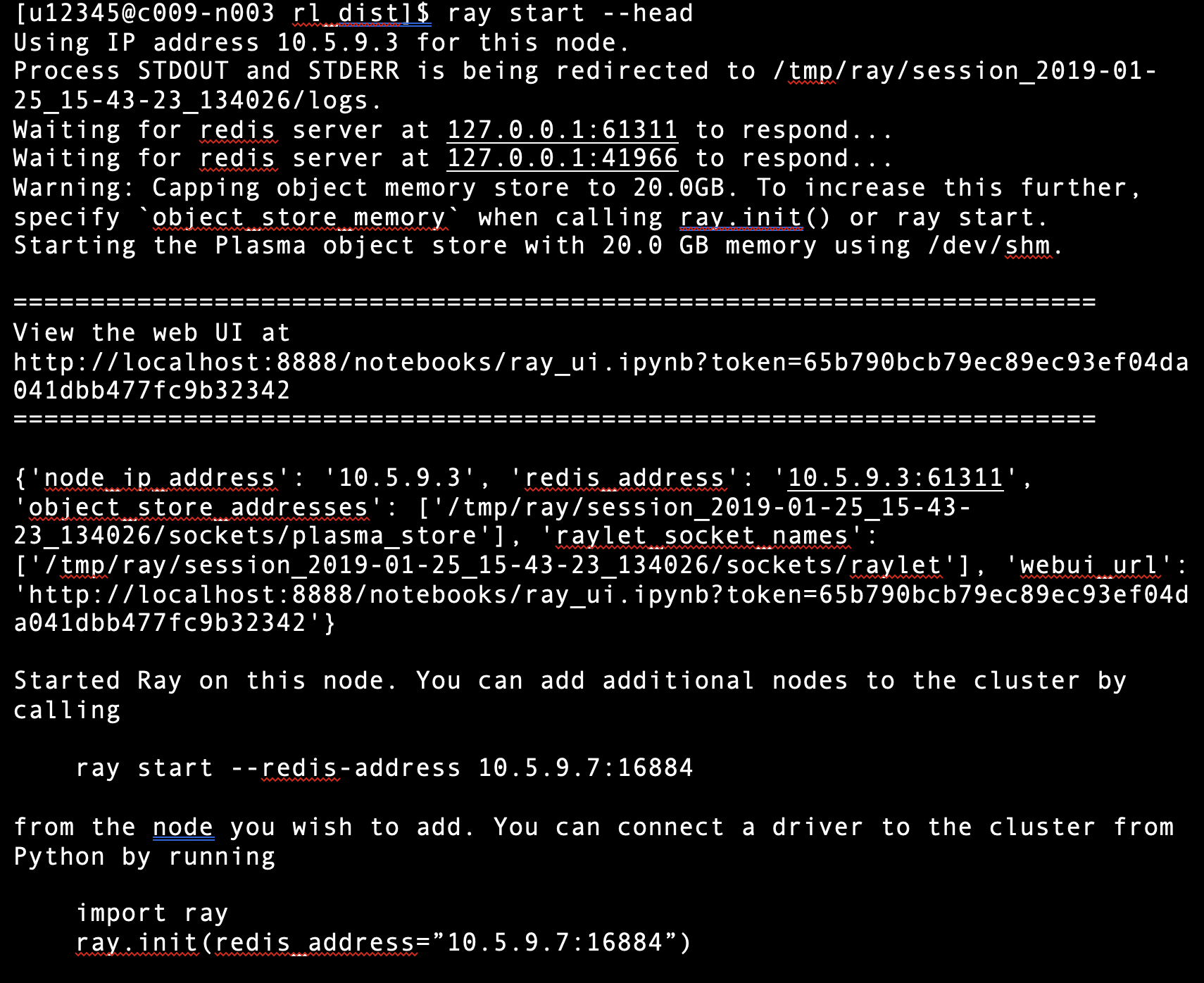

Then call py_create_workers.py to automatically add 5 workers. The numbers afterwards are the job IDs of the individual jobs where each Ray worker is running.

Using the get_nodes_addresses.py script shown previously, the connection between the head node and the worker nodes can be checked to get the expected number of unique IP addresses.

Now, when a2c_train.py is executed, it can be distributed across five other DevCloud nodes using Ray. In this simple example five nodes is not needed since in ray/python/ray/rllib/agents/agent.py, the common configuration for the number of CPUs per worker is only one as is the required CPUs allocated for the driver. However, with this simple example, the user can experiment with utilizing more CPUs, environments, number of A2C workers, and training batch size to get better performance.