Ray is an open source project for parallel and distributed Python. This article was originally posted here.
Parallel and distributed computing are a staple of modern applications. We need to leverage multiple cores or multiple machines to speed up applications or to run them at a large scale. The infrastructure for crawling the web and responding to search queries are not single-threaded programs running on someone’s laptop but rather collections of services that communicate and interact with one another.

The cloud promises unlimited scalability in all directions (memory, compute, storage, etc). Realizing this promise requires new tools for programming the cloud and building distributed applications.
This post will describe how to use Ray to easily build applications that can scale from your laptop to a large cluster.
Why Ray?
Many tutorials explain how to use Python’s multiprocessing module. Unfortunately the multiprocessing module is severely limited in its ability to handle the requirements of modern applications. These requirements include the following:
- Running the same code on more than one machine.
- Building microservices and actors that have state and can communicate.
- Gracefully handling machine failures.
- Efficiently handling large objects and numerical data.
Ray addresses all of these points, makes simple things simple, and makes complex behavior possible.

Necessary Concepts
Traditional programming relies on two core concepts: functions and classes. Using these building blocks, programming languages allow us to build countless applications.
However, when we migrate our applications to the distributed setting, the concepts typically change.
On one end of the spectrum, we have tools like OpenMPI, Python multiprocessing, and ZeroMQ, which provide low-level primitives for sending and receiving messages. These tools are very powerful, but they provide a different abstraction and so single-threaded applications must be rewritten from scratch to use them.
On the other end of the spectrum, we have domain-specific tools like TensorFlow for model training, Spark for data processing and SQL, and Flink for stream processing. These tools provide higher-level abstractions like neural networks, datasets, and streams. However, because they differ from the abstractions used for serial programming, applications again must be rewritten from scratch to leverage them.
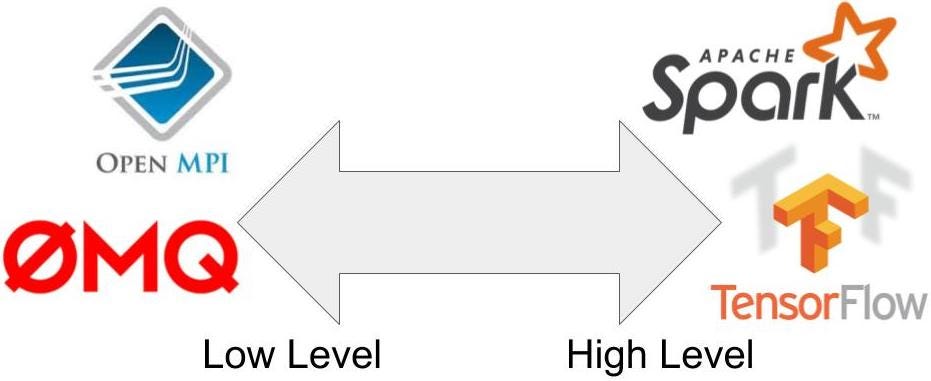
Tools for distributed computing on an axis from low-level primitives to high-level abstractions.
Ray occupies a unique middle ground. Instead of introducing new concepts. Ray takes the existing concepts of functions and classes and translates them to the distributed setting as tasks and actors. This API choice allows serial applications to be parallelized without major modifications.
Starting Ray
The ray.init() command starts all of the relevant Ray processes. On a cluster, this is the only line that needs to change (we need to pass in the cluster address). These processes include the following:
- A number of worker processes for executing Python functions in parallel (roughly one worker per CPU core).
- A scheduler process for assigning “tasks” to workers (and to other machines). A task is the unit of work scheduled by Ray and corresponds to one function invocation or method invocation.
- A shared-memory object store for sharing objects efficiently between workers (without creating copies).
- An in-memory database for storing metadata needed to rerun tasks in the event of machine failures.
Ray workers are separate processes as opposed to threads because support for multi-threading in Python is very limited due to the global interpreter lock.
Parallelism with Tasks
To turn a Python function f into a “remote function” (a function that can be executed remotely and asynchronously), we declare the function with the @ray.remote decorator. Then function invocations via f.remote() will immediately return futures (a future is a reference to the eventual output), and the actual function execution will take place in the background (we refer to this execution as a task).
Because the call to f.remote(i) returns immediately, four copies of f can be executed in parallel simply by running that line four times.
Task Dependencies
Tasks can also depend on other tasks. Below, the multiply_matrices task uses the outputs of the two create_matrix tasks, so it will not begin executing until after the first two tasks have executed. The outputs of the first two tasks will automatically be passed as arguments into the third task and the futures will be replaced with their corresponding values). In this manner, tasks can be composed together with arbitrary DAG dependencies.
Aggregating Values Efficiently
Task dependencies can be used in much more sophisticated ways. For example, suppose we wish to aggregate 8 values together. This example uses integer addition, but in many applications, aggregating large vectors across multiple machines can be a bottleneck. In this case, changing a single line of code can change the aggregation’s running time from linear to logarithmic in the number of values being aggregated.
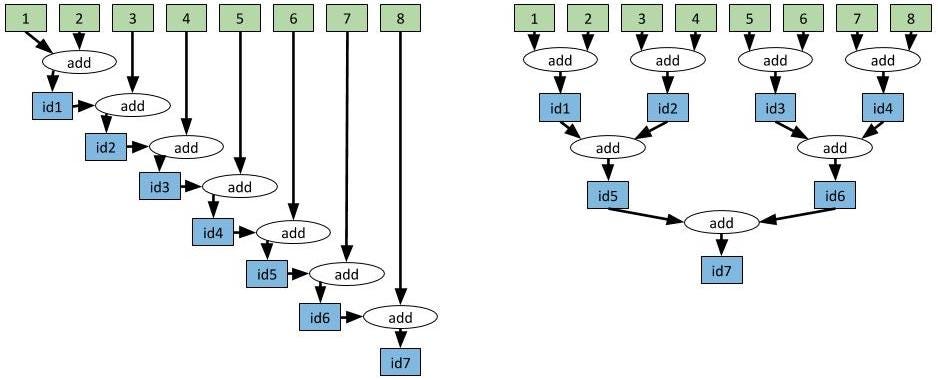
The dependency graph on the left has depth 7. The dependency graph on the right has depth 3. The computations yield the same result, but the one on the right is much faster.
As described above, to feed the output of one task as an input into a subsequent task, simply pass the future returned by the first task as an argument into the second task. This task dependency will automatically be taken into account by Ray’s scheduler. The second task will not execute until the first task has finished, and the output of the first task will automatically be shipped to the machine on which the second task is executing.
The above code is very explicit, but note that both approaches can be implemented in a more concise fashion using while loops.
From Classes to Actors
It’s challenging to write interesting applications without using classes, and this is as true in the distributed setting as it is on a single core.
Ray allows you to take a Python class and declare it with the @ray.remote decorator. Whenever the class is instantiated, Ray creates a new “actor”, which is a process that runs somewhere in the cluster and holds a copy of the object. Method invocations on that actor turn into tasks that run on the actor process and can access and mutate the state of the actor. In this manner, actors allow mutable state to be shared between multiple tasks in a way that remote functions do not.
Individual actors execute methods serially (each individual method is atomic) so there are no race conditions. Parallelism can be achieved by creating multiple actors.
The above example is the simplest possible usage of actors. The line Counter.remote() creates a new actor process, which has a copy of the Counter object. The calls to c.get_value.remote() and c.inc.remote() execute tasks on the remote actor process and mutate the state of the actor.
Actor Handles
In the above example, we only invoked methods on the actor from the main Python script. One of the most powerful aspects of actors is that we can pass around handles to an actor, which allows other actors or other tasks to all invoke methods on the same actor.
The following example creates an actor that stores messages. Several worker tasks repeatedly push messages to the actor, and the main Python script reads the messages periodically.
Actors are extremely powerful. They allow you to take a Python class and instantiate it as a microservice which can be queried from other actors and tasks and even other applications.
Tasks and actors are the core abstractions provided by Ray. These two concepts are very general and can be used to implement sophisticated applications including Ray’s builtin libraries for reinforcement learning, hyperparameter tuning, speeding up Pandas, and much more.
Learn More About Ray
- Check out the code on GitHub.
- View the Ray documentation.
- Ask and answer questions on StackOverflow.
- Discuss development on ray-dev@googlegroups.com.
- Check out libraries built with Ray for reinforcement learning, hyperparameter tuning, and speeding up Pandas.