Confluo is a system for real-time distributed analysis of multiple data streams. Confluo simultaneously supports high throughput concurrent writes, online queries at millisecond timescales, and CPU-efficient ad-hoc queries via a combination of data structures carefully designed for the specialized case of multiple data streams, and an end-to-end optimized system design.
We are excited to release Confluo as an open-source C++ project, comprising:
- Confluo’s data structure library, that supports high throughput ingestion of logs, along with a wide range of online (live aggregates, conditional trigger executions, etc.) and offline (ad-hoc filters, aggregates, etc.) queries, and,
- A Confluo server implementation, that encapsulates the data structures and exposes its operations via an RPC interface, along with client libraries in C++, Java and Python.
We have evaluated Confluo for several different application scenarios, including:
- A network monitoring and diagnosis framework, where Confluo is able to execute thousands of triggers and tens of filters at line rate (for 10Gbps links) on a single core.
- A time-series database, where Confluo achieves 2-20x higher throughput, 2-10x lower latency for inserts, and 1.5x-5x higher throughput, 5-20x lower latency for time-range queries compared to state-of-the-art time-series databases: CorfuDB, TimescaleDB, and BTrDB.
- A pub-sub system, where Confluo outperforms Apache Kafka by a factor of 4-10x for publish-subscribe throughput.
Confluo Overview
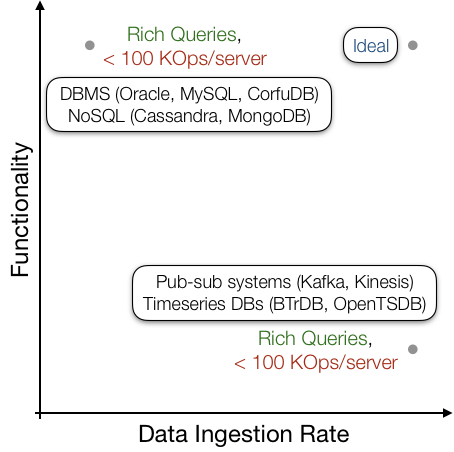 Many modern applications, e.g., end-host based network monitoring, IoT and connected homes, and data center operational services, capture tens of millions of data points per second per backing server. This data is used in online queries for visualization and monitoring purposes, and in offline queries for root-cause analysis and system optimizations. Enabling these applications require real-time monitoring and analysis tools that can support high throughput data ingestion, low-latency online queries, and low-overhead offline queries.
Many modern applications, e.g., end-host based network monitoring, IoT and connected homes, and data center operational services, capture tens of millions of data points per second per backing server. This data is used in online queries for visualization and monitoring purposes, and in offline queries for root-cause analysis and system optimizations. Enabling these applications require real-time monitoring and analysis tools that can support high throughput data ingestion, low-latency online queries, and low-overhead offline queries.
While data structures exist for high throughput data ingestion, and for supporting expressive online and offline queries, the two have so far remained mutually exclusive. Supporting the aforementioned queries requires updating several data structures — for storing raw data, aggregate statistics, and materialized views across multiple attributes — while ingesting data from multiple streams. Unfortunately, data structures for supporting these tend to have high update overheads, and are unable to sustain the data ingestion rates required for most applications. On the other hand, data structures that can sustain high data ingestion rates tend to only support very simplistic queries.
To address this challenge, we’ve built Confluo, a system that strives to achieve both high throughput data ingestion and expressive offline and online queries simultaneously.
Assumptions
Confluo achieves the ambitious goals outlined above by exploiting its target application semantics to make simplifying assumptions for the underlying system. Confluo’s main simplifying assumptions are:
- Application data streams exhibit write-once semantics (i.e., data is append-only),
- Applications for monitoring and diagnosis use fixed-size attributes (e.g., fixed-width header fields in network packets; 64-bit timestamp and temperature readings in distributed sensor networks (IoT); floating-point precision CPU and memory statistics in data center operational metrics, etc.).
- Applications do not require transactional semantics for concurrent operations, atomicity semantics is sufficient.
Confluo API
Confluo operates on data streams. Each stream comprises of records, each of which follows a predefined schema over a collection of strongly-typed attributes. As mentioned above Confluo currently supports only fixed-size attributes; this includes primitive data types such as binary, integral or floating-point values, or domain-specific types such as IP addresses, ports, sensor readings, etc.
A schema in Confluo is a collection of strongly-typed attributes. It is specified via JSON like semantics; for instance, consider the example below for a simple schema with five attributes:
{
timestamp: LONG,
op_latency_ms: DOUBLE,
cpu_util: DOUBLE,
mem_avail: DOUBLE,
log_msg: STRING(100)
}
Currently, Confluo only supports streams with fixed schemas, i.e., each record in the stream must conform to the schema provided.
To speed up ad-hoc offline queries, applications can add indexes for individual attributes in the schema. To support online queries, Confluo also employs a match-action language with three main elements: filters, aggregates and triggers.
- A Confluo filter is an expression comprising of relational and boolean operators (see table below) over arbitrary subset of bounded-width attributes, and identifies records that match the expression.
| Operator | Example | |
|---|---|---|
| Relational | Equality | dst_port=80 |
| Range | cpu_util>.8 |
|
| Boolean | Conjunction | volt>200 && temp>100 |
| Disjunction | cpu_util>.8 || mem_avail<.1 |
|
| Negation | transport_protocol != TCP |
|
- A Confluo aggregate (see table below) evaluates a computable function on an attribute for all records that match a certain filter expression.
| Aggregator | Example |
|---|---|
| SUM, COUNT | COUNT(pkt), SUM(pktSize) |
| AVG | AVG(cpu_util) |
| MIN, MAX | MIN(volt), MAX(temp) |
- Finally, a Confluo trigger is a boolean conditional (e.g., <, >, =, etc.) evaluated over a Confluo aggregate.
| Example: | latency_trigger: MAX(latency_ms) > 100 |
|---|
Confluo supports indexes, filters, aggregates and triggers only on fixed-size attributes in the schema. Once added, each of these are evaluated and updated upon arrival of each new batch of data records. We note that Confluo currently does not support joins, since they are uncommon in most monitoring and diagnosis applications.
Implementation
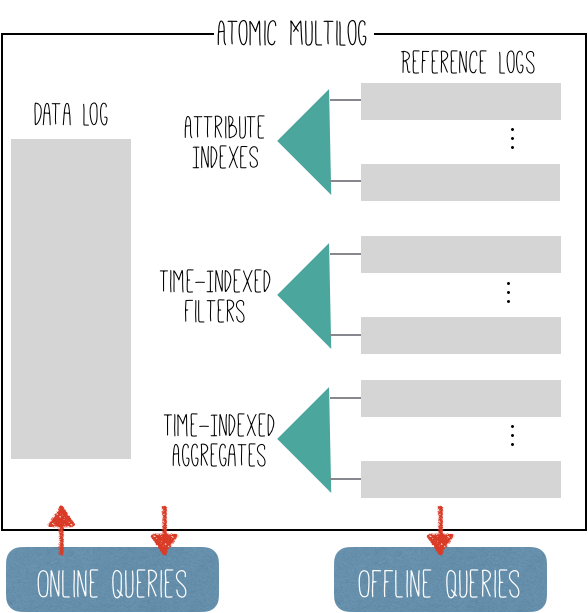 Confluo’s basic storage abstraction for data streams is a new data structure: Atomic MultiLog, a collection of lock-free concurrent logs that stores raw data, aggregate statistics and materialized views, and uses new techniques to efficiently update the entire collection as a single atomic operation. Atomic MultiLog exploits the application workload assumptions outlined above to facilitate both high throughput data ingestion, as well as rich online and offline queries.
Confluo’s basic storage abstraction for data streams is a new data structure: Atomic MultiLog, a collection of lock-free concurrent logs that stores raw data, aggregate statistics and materialized views, and uses new techniques to efficiently update the entire collection as a single atomic operation. Atomic MultiLog exploits the application workload assumptions outlined above to facilitate both high throughput data ingestion, as well as rich online and offline queries.
Atomic MultiLogs are similar in interface to database tables. In order to store data from different streams, applications can create an Atomic MultiLog with a pre-defined schema, and write data streams that conform to the schema. Applications then create indexes, filters, aggregates and triggers on the Atomic MultiLog to enable various monitoring and diagnosis functionalities, as described above.
For more resources on Confluo implementation and usage, take a look at its modes of operation, data storage, query execution, and quick start guides. For details on the Atomic MultiLog and Confluo architecture, see our upcoming NSDI’19 paper, which focuses on Confluo’s application to network monitoring and diagnosis.
Performance
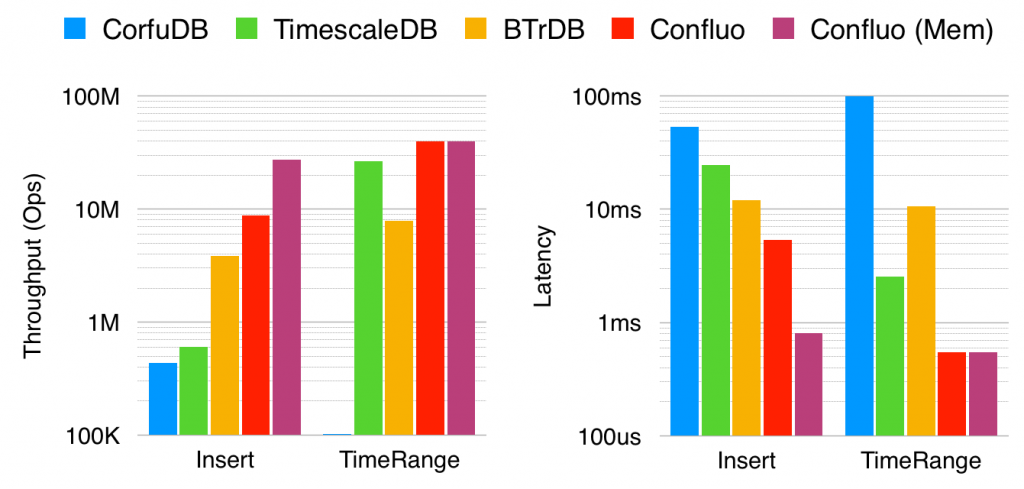
We have evaluated Confluo against a wide range of applications, including network monitoring and diagnosis, time-series databases, and pub-sub systems. The figure demonstrates Confluo’s performance for the time-series database application, and compares it against BTrDB, CorfuDB, and TimescaleDB on an EC2 c4.8xlarge instance with 18 CPU cores and 60GB RAM. We used a 500 million record subset of the Open uPMU Dataset, a real-world trace of voltage, current and phase readings collected from a number of µPMUs installed in a power-grid, over a three month period. Requests are issued as continuous streams with 8K record batches.
We observed that systems like CorfuDB and TimescaleDB achieve over 10x lower performance than BTrDB and Confluo. Note that this is not a shortcoming: CorfuDB and TimescaleDB support stronger (transactional) semantics than BTrDB and Confluo. Thus, depending on desired semantics, either class of systems may be useful for an underlying application. All in all, Confluo achieves 2-20x higher throughput and 2-10x lower latency for inserts, and 1.5x-5x higher throughput and 5-20x lower latency for time-range filters compared to state-of-the-art time-series databases.
Results on the network monitoring and diagnosis tool can be found in our upcoming NSDI paper, while results for the pub-sub system can be found here.
Limitations
As we have already noted, Confluo makes certain simplifying assumptions to enable a wide range of online and offline queries efficiently, while supporting ingestion of tens of millions of data points per server. As such, Confluo only supports attributes in data streams that can be represented with a fixed number of bits. Moreover, Confluo currently only supports streams with rigid schemas, although we’re working hard towards supporting more flexible schemas.
Looking Ahead
We’re working on several interesting projects to make Confluo more expressive and efficient. Some of these include support for approximate queries on data streams using sketches, support for a rich SQL interface on data streams, and lower level performance improvements via file consolidation and memory pooling. To find out more about Confluo, we encourage you to visit our project website and GitHub repository.
Comments 1
Pingback: If you did not already know | AnalytiXon