This was originally posted on the Ray blog.
We are pleased to announce the Ray 0.2 release. This release includes the following:
- substantial performance improvements to the Plasma object store
- an initial Jupyter notebook based web UI
- the start of a scalable reinforcement learning library
- fault tolerance for actors
Plasma
Since the last release, the Plasma object store has moved out of the Ray codebase and is now being developed as part of Apache Arrow (see the relevant documentation), so that it can be used as a standalone component by other projects to leverage high-performance shared memory. In addition, our Arrow-based serialization libraries have been moved into pyarrow (see the relevant documentation).
In 0.2, we’ve increased the write throughput of the object store to around 15GB/s for large objects (when writing from a single client). Achieving this performance requires enabling huge pages (to minimize the number of TLB cache misses). Instructions for doing so are here.
The speed at which objects can be written into the object store is a key performance metric. For example, it is the bottleneck for A3C and many other algorithms.
Web UI
We’ve built an initial Jupyter-notebook-based web UI for understanding and debugging application performance. See the instructions for using the UI. The UI includes a task timeline visualization based on Chrome tracing to see where tasks were scheduled, how long they took, and what the dependencies between the tasks were. An example visualization is shown below.
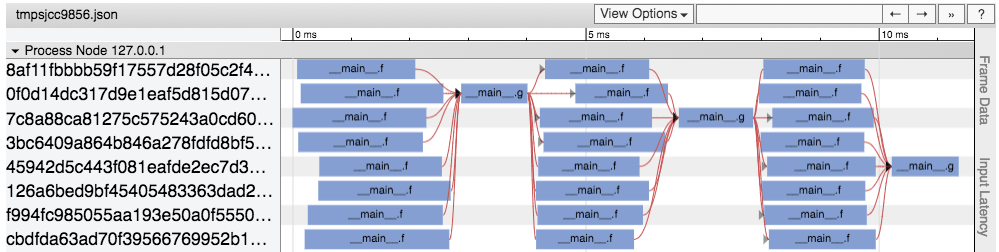
A visualization of the task timeline. Boxes indicate tasks and arrows indicate data dependencies between tasks.
This type of visualization can immediately expose problems with performance, scheduling, and load balancing.
RLlib
We’ve begun implementing a scalable reinforcement learning library based on Ray. So far it includes implementations of the following algorithms.
- Proximal policy optimization (PPO)
- Deep Q-learning (DQN)
- Asynchronous advantage actor critic (A3C)
- Evolution Strategies (ES)
The DQN, A3C, and ES implementations are based on the OpenAI baselines. Example code for training is available in the original blog post.
This uses proximal policy optimization to train a policy to control an agent in the CartPole environment.
Running this (on the Humanoid-v1 environment to train a walking humanoid robot) on AWS with a cluster of fifteen m4.16xlarge instances and one p2.16xlarge instance, we achieve a reward of over 6000 in around 35 minutes. The rollouts are parallelized over 512 physical cores and the policy optimization is parallelized over 6 GPUs. Relevant hyperparameters for this experiment are here.
This RL library is under development, and we are looking for contributions including implementations of more algorithms.
Actor fault tolerance
We’ve enabled fault tolerance for actors as follows. If a machine fails, the actors that were running on that machine are recreated on other machines, and the tasks that previously executed on those actors are replayed to recreate the state of the actor. We are working on improving the speed of recovery by enabling actor state to be restored from checkpoints. See an overview of fault tolerance in Ray.