This work was done in collaboration with Ding Ding and Sergey Ermolin from Intel.
In recent years, the scale of datasets and models used in deep learning has increased dramatically. Although larger datasets and models can improve the accuracy in many AI applications, they often take much longer to train on a single machine. However, it is not very common to distribute the training to large clusters using current popular deep learning frameworks, compared to what’s been long around in the Big Data area, as it’s often harder to gain access to a large GPU cluster and lack of convenient facilities in popular DL frameworks for distributed training. By leveraging the cluster distribution capabilities in Apache Spark, BigDL successfully performs very large-scale distributed training and inference.
In this article, we will demonstrate how a parameter server (PS) style of parameter synchronization (using peer-to-peer allreduce) in BigDL, to reduce the communication overhead, along with coarse-grained scheduling, is able to provide significant speedups for large scale distributed deep learning training.
What is BigDL
BigDL is a distributed deep learning library for Apache Spark developed by Intel and contributed to the open source community for the purposes of uniting big data processing and deep learning. The goal of BigDL is to help make deep learning more accessible to the Big Data community, by allowing them to continue the use of familiar tools and infrastructure to build deep learning applications.
As shown in Figure 1, BigDL is implemented as a library on top of Spark, so that users can write their deep learning applications as standard Spark programs. As a result, it can be seamlessly integrated with other libraries on top of Spark (e.g., Spark SQL and Dataframes, Spark ML pipelines, Spark Streaming, Structured Streaming, etc.), and can directly run on existing Spark or Hadoop clusters.
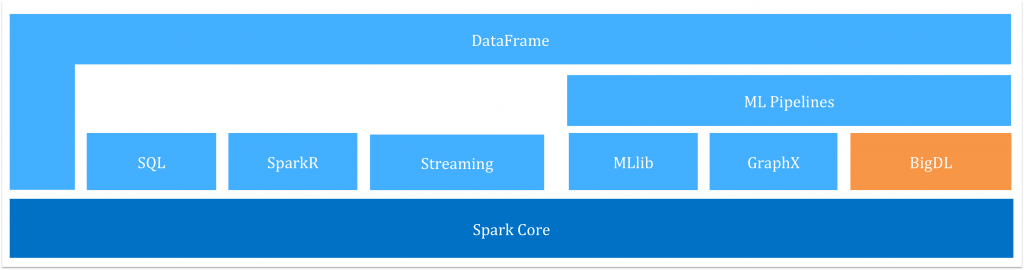
Figure 1: BigDL in relation to Apache Spark components
Communications in BigDL
In Spark MLlib, a number of machine learning algorithms are based on using synchronous mini-batch SGD. To aggregate parameters these algorithms use the reduce or treeAggregate methods in Spark as shown in Figure 2.
In this process, the time spent at the driver linearly increases with the number of nodes. This is both due to the CPU and network bandwidth limitations of the driver. The CPU cost arises from merging partial results while the network cost incurred is a result of transferring one copy of the model from each of the tasks (or partitions). Thus the centralized driver becomes a bottleneck when there are a large number of nodes in the cluster.
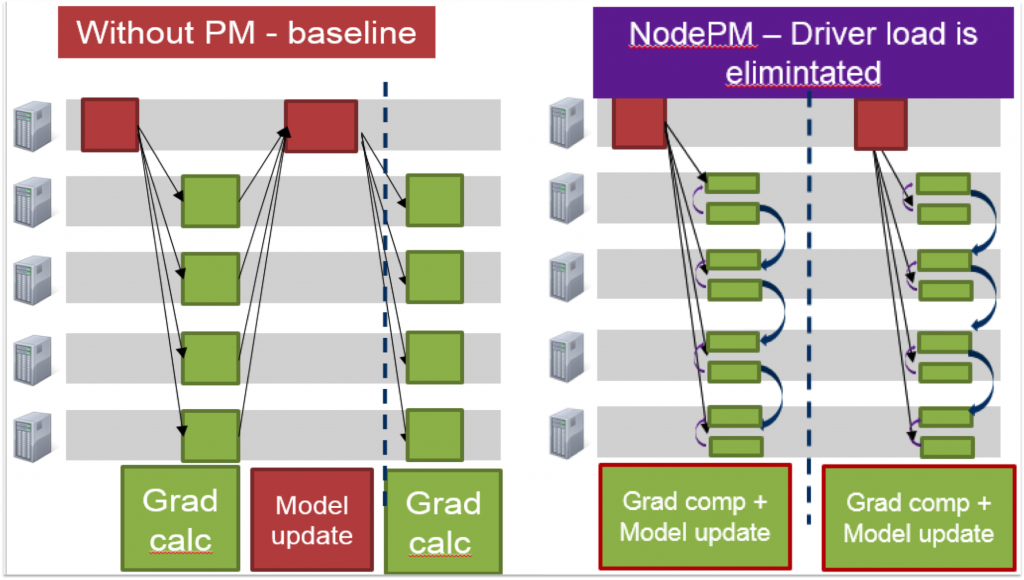
Figure 2: Comparison of parameter synchronization in MLlib (left) and BigDL (right)
Figure 2 shows how Parameter Managers inside BigDL implement a PS architecture (through AllReduce operation) for synchronous mini-batch SGD. After each task computes its gradients, instead of sending gradients back to driver, gradients from all the partitions within a single worker are aggregated locally. Then each node will have one gradient: this ensures that data transferred on each node will not increase if we increase the number of partitions in a node. After that the aggregated gradient on each node is sliced into chunks and these chunks are exchanged between all the nodes in the cluster. Each node is responsible for a specific chunk, which in essence implements a PS architecture in BigDL for parameter synchronization. Each node retrieves gradients for the slice of the model that this node is responsible for from all the other nodes and aggregates them in multiple threads. After the pair-wise exchange completes, each node has its own portion of aggregated gradients and uses this to update its own portion of weights. Then the exchange happens again for synchronizing the updated weights. At the end of this procedure, each node will have a copy of the updated weights.
As the parameters are stored in Spark Block Manager, each task can get the latest weights from it. As all nodes in the cluster play the same role and the driver is not involved in the communication, there is no bottleneck in the system. Besides, as the cluster grows, data size transferred on each node remains the same and thus lowers the time spent in parameter aggregation, enabling BigDL to achieve near-linear scaling. Figure 3 shows that for Inception V1, the throughput of 16 nodes is ~1.92X of 8 nodes, while for ResNet, it is ~1.88X. These results show that BigDL achieves a near linear scale out performance.
However, we find that increasing the number of partitions still leads to increase in training time. Our profiling showed this increase was because of the significant scheduling overhead present in Spark for low latency applications. Figure 4 shows the scheduling overheads as a fraction of average compute time for Inception V1 training as we increase the number of partitions. We see that with partition numbers greater than 300, Spark overheads takes up more than 10% of average compute time and thus slow down the training process. To work around this issues, currently BigDL just runs a single task (working on a single partition) on each worker, and each task in turn runs multiple threads in the deep learning training.
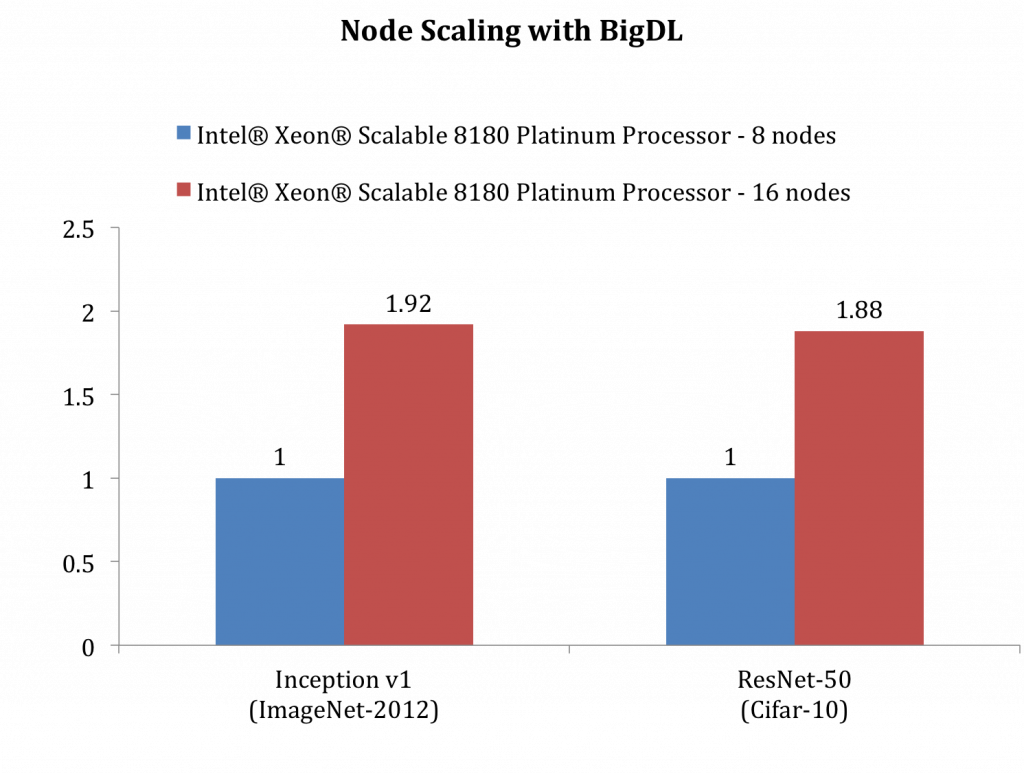
Figure 3: BigDL scaling behavior
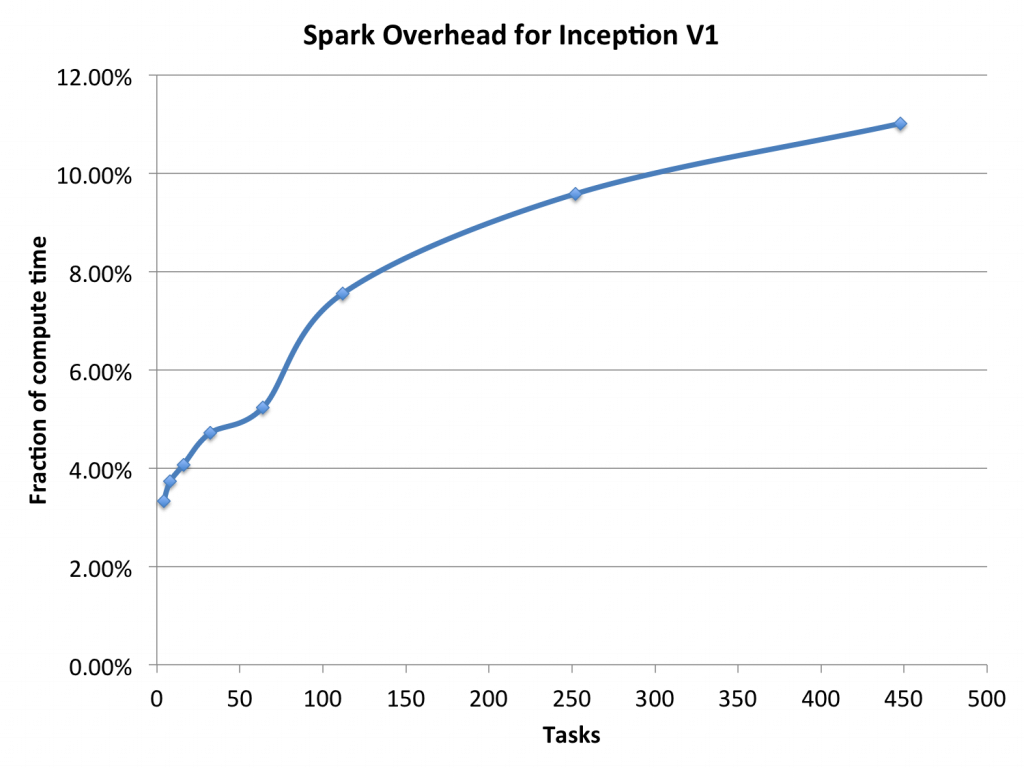
Figure 4: Spark overhead as a fraction of compute time for training InceptionV1
What is Drizzle
Drizzle is a research project at the RISELab to study low latency execution for streaming and machine learning workloads. Currently, Spark uses a BSP computation model, and notifies the scheduler at the end of each task. Invoking the scheduler at the end of each task adds overheads and results in decreased throughput and increased latency. We observe for that for many low-latency workloads, the same operations are executed repeatedly, e.g., processing different batches in streaming, or iterative model training in machine learning. Based on this observation, we find that we can improve performance by amortizing the number of times the scheduler is invoked.
In Drizzle, we introduce group scheduling, where multiple iterations (or a group) of computation are scheduled at once. This helps decouple the granularity of task execution from scheduling and amortize the costs of task serialization and launch. One key challenge here is in launching tasks before their input dependencies have been computed. We solve this using pre-scheduling in Drizzle, where we proactively queue tasks to be run on worker machines, and rely on workers to trigger tasks when their input dependencies are met.
How Drizzle works with BigDL
In order to exploit the scheduling benefits provided by Drizzle, we modified the implementation of distributed optimization algorithm in BigDL. The main changes we made include refactoring the multiple stages of computation (like gradient calculation, gradient aggregation etc.) to be part of a single DAG of stages submitted to the scheduler. This refactoring enables Drizzle to execute all the stages of computation without interacting with the centralized driver for control plane operations. Thus when used in conjunction with the above described Parameter Manager, we can execute BigDL iterations without any centralized bottleneck in the control plane and data plane.
Performance
We performed performance benchmarks to measure the benefits from using BigDL. These benchmarks were run using Inception V1 on ImageNet and Vgg on Cifar-10 on Amazon EC2 clusters. We used r4.x2large machines where each machine has 4 cores. We configured BigDL to use 1 partition per-core.
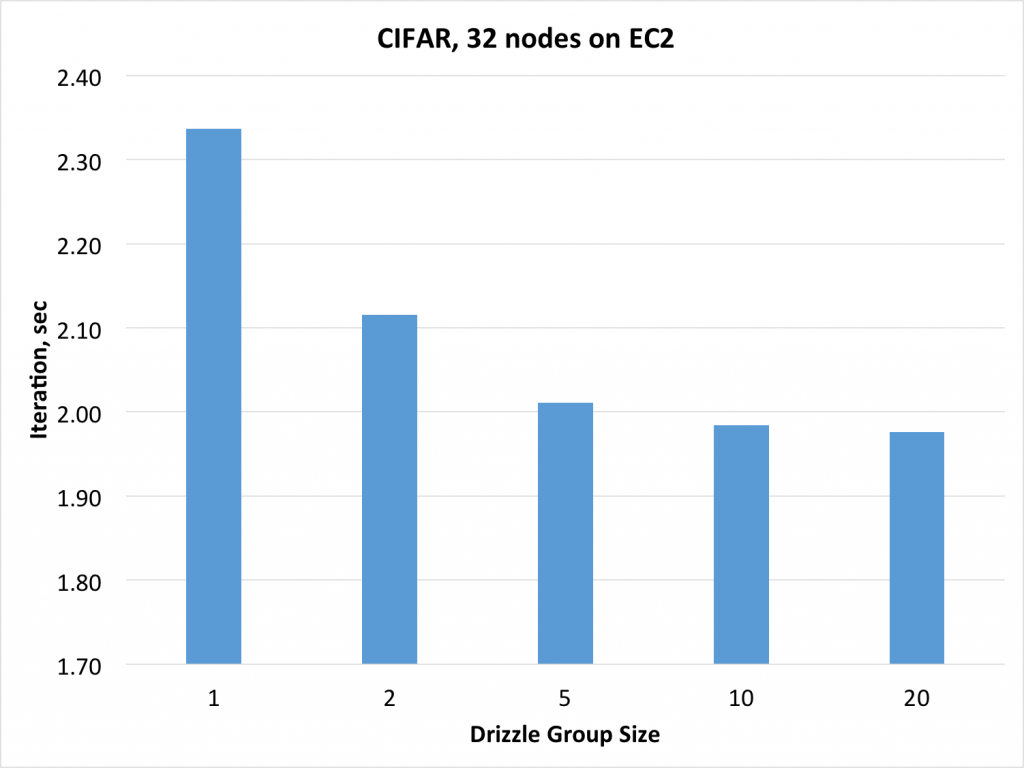
Figure 5: Drizzle with VGG on CIFAR-10
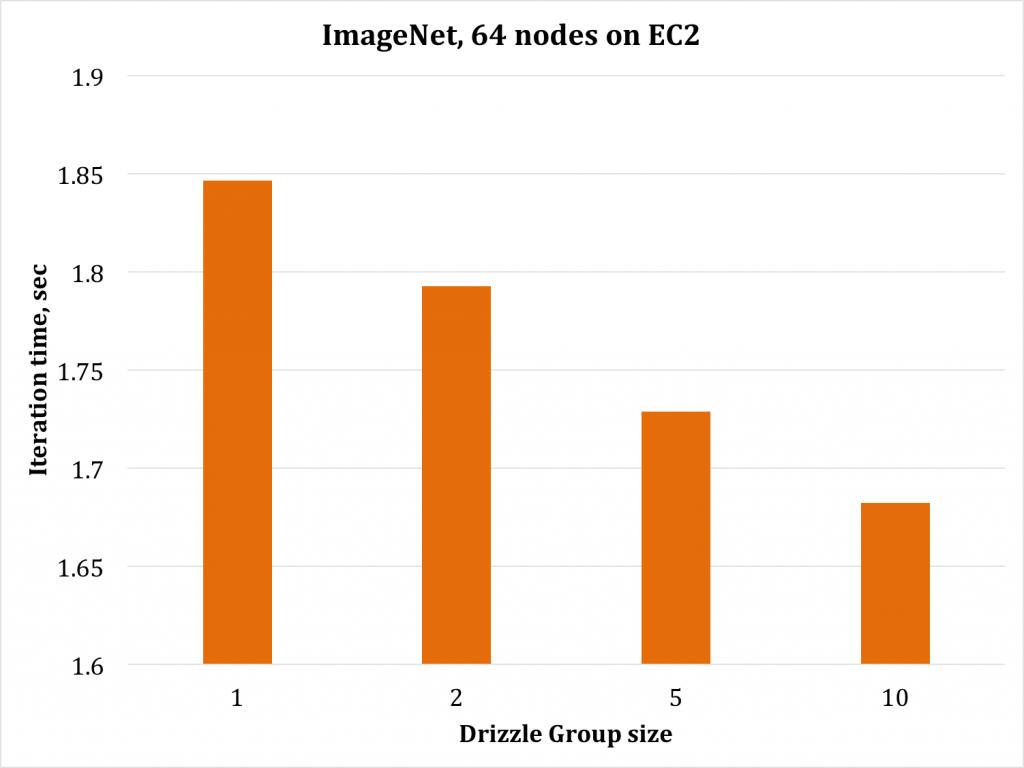
Figure 6: Drizzle with Inception V1 on ImageNet
Figure 5 shows that for Vgg on 32 nodes, there is a 15% improvement when using Drizzle with group size 20. For Inception V1 on 64 nodes, (Figure 6), there is constantly performance improve when increasing group size in Drizzle and that there is 10% improvement with a group size of 10. These improvements map directly to the scheduling overheads that we observed without Drizzle in Figure 4.
Summary
In this blog post, we demonstrated how BigDL performs parameter aggregation and how Drizzle reduces Spark scheduling overhead. To get started with BigDL with Drizzle, try out the BigDL parameter manager with drizzle GitHub page; and to learn more about our work, please check out the BigDL GitHub page and Drizzle GitHub page.